# 架构分析
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
本篇文章以InnoDB为主
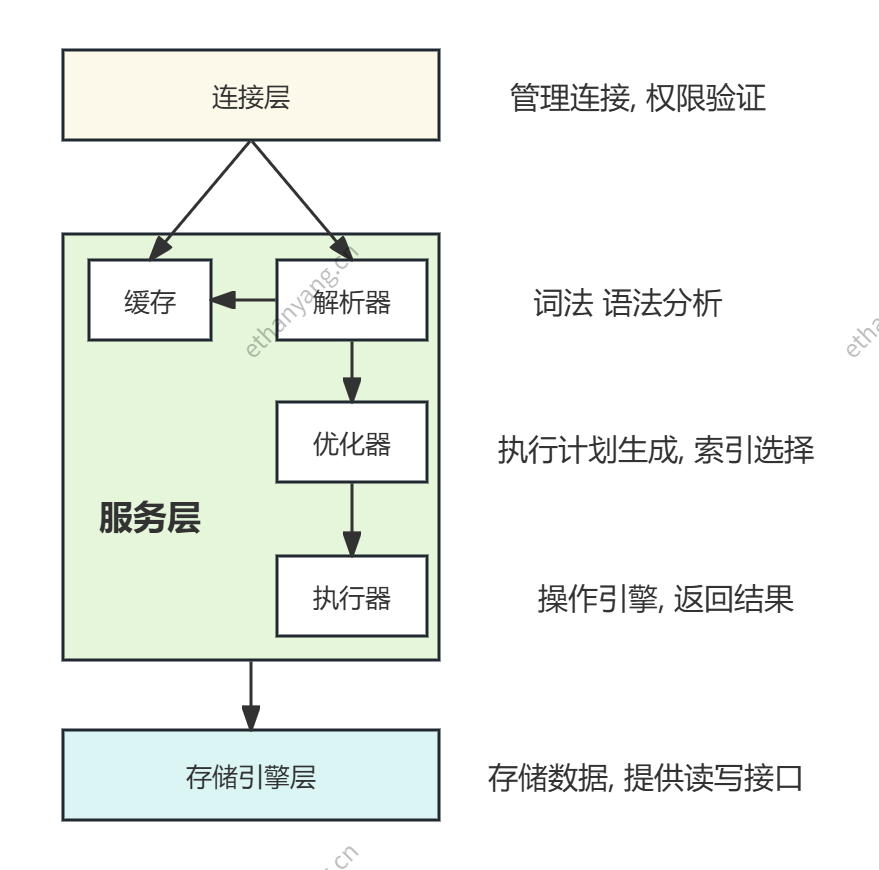
# MySql架构分层
MySql可分为三层, 和客户对接的连接层, 真正执行操作的服务层, 和硬件打交道的存储引擎层。
# SQL执行流程
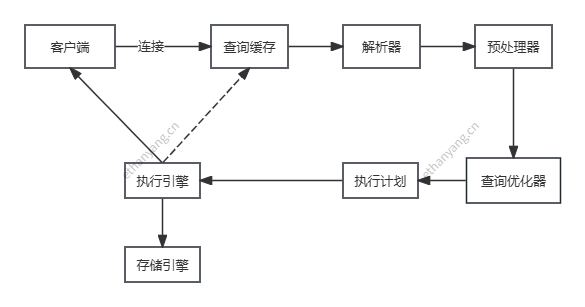
# 查询SQL是怎么执行的?
我们按照上述流程图逐步分析
# 1. 连接
MySQL 默认监听端口 3306,每当客户端(如 JDBC、Navicat)建立连接时,服务器会为其分配一个线程。每个连接就是一次“会话”,线程的创建与销毁直接关系到资源使用。
由于线程是系统资源,长期未活动的连接(通常处于 SLEEP 状态)会被 MySQL 根据超时机制关闭,以释放资源。
以下是常用的连接/线程管理相关 SQL 查询:
-- 当前连接数统计(包括活动连接和 SLEEP 连接)
SHOW GLOBAL STATUS LIKE 'Threads%';
-- 非交互式连接超时时间(如 JDBC 客户端)
SHOW GLOBAL VARIABLES LIKE 'wait_timeout';
-- 交互式连接超时时间(如 Navicat、命令行)
SHOW GLOBAL VARIABLES LIKE 'interactive_timeout';
-- 最大并发连接数限制
SHOW GLOBAL VARIABLES LIKE 'max_connections';
2
3
4
5
6
7
8
9
10
11
GLOBAL与SESSION的区别:GLOBAL作用于整个 MySQL 实例,适用于所有连接;SESSION仅作用于当前会话(即连接),默认使用SESSION级别。
# 2. 查询缓存
在 MySQL 8.0 之前,MySQL 提供了查询缓存功能,用于缓存 SELECT 查询结果。该功能默认关闭,即使开启,也不推荐使用,原因如下:
不推荐原因:
- 匹配严格:SQL 必须完全一致(包括大小写、空格)才能命中缓存;
- 易失效:只要表中有任意数据变动,相关缓存全部失效;
- 并发瓶颈:多个线程访问同一缓存会引发锁竞争,反而影响性能。
因此,查询缓存已在 MySQL 8.0 被彻底移除,更推荐使用:
- 应用层缓存(如 Redis);
- ORM 框架(如 MyBatis、Hibernate)内置缓存机制;
- 分布式缓存服务,实现灵活的缓存策略和粒度控制。
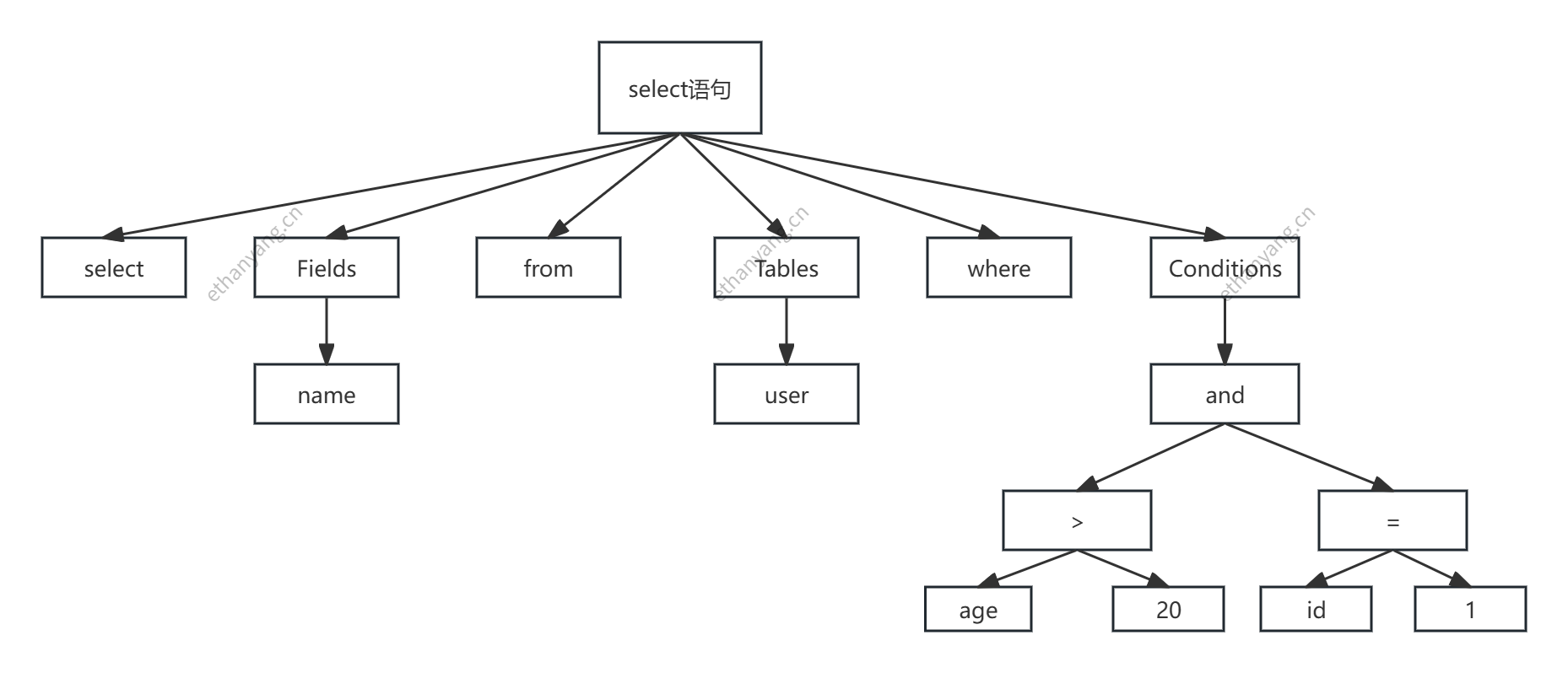
# 3. 语法解析和预处理
SQL 能被识别执行,是通过解析过程完成的,主要分为三步:词法解析、语法解析、预处理。
词法解析
将整条 SQL 拆分为一个个词法单元(如关键字、表名、字段名等),并标记它们的类型和位置。
select name from user where id = 1 and age > 20;1会将这个SQL变为8个符号, 每个符号什么类型, 从哪里开始到哪里结束。
语法解析
根据 MySQL 的语法规则,对词法单元进行语法检查,并生成解析树。
![]()
预处理器
在解析树的基础上,进一步检查表、字段是否存在等语义问题,确保语句的正确性。
SQL 注入从根本上是因为拼接 SQL 导致语法树被用户输入改变,而 预处理器(Prepared Statement) 是主要解决方案,真正把 SQL 和参数分离,也就是用户传入的值无法影响SQL编译。
# 4. 查询优化与查询执行计划
一条 SQL 通常有多种执行方式,查询优化器会根据解析树生成多个执行计划,并选择成本最低的一种作为最终执行方案。
可通过以下命令查看上次查询的开销:
# 查询开销最小的执行计划
show status like `last_query_cost`;
2
优化器将解析树转化为执行计划,可使用 EXPLAIN 查看:
# 查询执行计划
EXPLAIN select name from user where id = 1 and age > 20;
# 查询执行计划详细信息
EXPLAIN FORMAT=JSON select name from user where id = 1 and age > 20;
2
3
4
5
# 5. 存储引擎
得到执行计划后,下一步就是实际执行 SQL 并访问数据。那么问题来了:
- 数据存储在哪里?
- 谁来真正执行这些操作?
这就涉及到了 MySQL 的存储引擎。
存储引擎是负责 数据的存储、读取、更新和删除 的组件,不同的存储引擎实现方式不同,适用于不同的场景。MySQL 通过 插件式架构 支持多种存储引擎,常见的有:
| 存储引擎 | 特点简介 | 是否支持事务 |
|---|---|---|
| InnoDB | 默认引擎,支持事务、行级锁、崩溃恢复,适合高并发 | ✅ |
| MyISAM | 不支持事务,查询快,占用空间小,适合读多写少场景 | ❌ |
| Memory | 数据存储在内存中,速度快,重启即失效 | ❌ |
| Archive | 适合归档场景,只支持插入和查询,压缩存储 | ❌ |
| CSV | 以 CSV 文件形式存储数据,易于数据交换 | ❌ |
执行计划最终由存储引擎负责调取底层数据完成 SQL 操作,因此选用合适的存储引擎对性能影响极大。
✅ 说明:从 MySQL 5.5 起,InnoDB 成为默认存储引擎,几乎支持所有主流业务场景。
如需更深入了解某个存储引擎,可以使用以下命令查看当前数据库的默认引擎及表使用的引擎:
-- 查看默认存储引擎
SHOW VARIABLES LIKE 'storage_engine';
-- 查看指定表的存储引擎
SHOW TABLE STATUS LIKE 'your_table_name'\G
2
3
4
5
# 6. 执行引擎
虽然 存储引擎 负责数据的实际存取,但真正“操作”数据的,是 执行引擎(SQL 执行器)。
执行引擎的职责是: 按照优化器生成的执行计划,驱动存储引擎完成对应的数据操作。
可以理解为:
- 优化器:告诉你“怎么做更高效”(制定计划)
- 执行引擎:负责“按计划执行任务”
- 存储引擎:提供“工具和原材料”(数据存取能力)
# 更新SQL是怎么执行的?
对于SQL而言, 更新操作实际上包括了增删改几个动作, MyBatis源码中, Executor也只有doQuery() 以及 doUpdate()的方法, 并没有增删, 其基本流程和查询类似, 也要经过解析器 优化器的处理交给执行器执行, 不同之处在于拿到符合条件之后的操作。
# 1. 缓冲池 Buffer Pool
InnoDB 将所有数据持久化存储在磁盘上,而磁盘 I/O 相对较慢,因此在访问数据时,会先将数据从磁盘加载到内存中操作。为了提高读写效率,InnoDB 引入了 缓冲池(Buffer Pool),用于缓存磁盘中的数据页。
InnoDB 中的数据按 页(Page) 为单位管理,每页大小为 16KB。当查询一条记录时,InnoDB 并不会只加载这一行,而是将该记录所在的整个数据页载入缓冲池。根据局部性原理,查询时往往还会顺带加载相邻的多个数据页,提高后续访问命中率。
当数据被修改时,InnoDB 会先在缓冲池中进行更新,而不会立即写入磁盘。这些已被修改但尚未同步到磁盘的页被称为脏页(Dirty Page)。InnoDB 通过后台线程定期将脏页刷新到磁盘,这一过程称为刷脏(Flush Dirty Pages),用于保证数据持久性和一致性。
总结: 缓冲池是 InnoDB 存储引擎中的核心组件,用于减少磁盘访问频率,从而大幅提升 MySQL 的读写性能。
# 2. Redo Log(重做日志)
在 InnoDB 中,数据的修改操作并不会立刻持久化到磁盘,而是先写入内存中的缓冲池(Buffer Pool)。为了提高性能,后台线程会延迟将脏页(已修改但未落盘的页)写入磁盘,这个过程称为“刷脏”。
但问题是:如果在刷脏之前服务器宕机,缓冲池中尚未写入磁盘的数据就会丢失,这就会破坏事务的持久性(Durability)。
为了解决这个问题,InnoDB 引入了 Redo Log(重做日志)机制:
记录内容:
- 物理级别的日志
- 记录 数据页(page)修改后的内容,包括页号、偏移量、新值等
- 每条修改都与事务 ID 相关,便于恢复时判断事务状态
触发条件:
任何修改 数据页的操作(INSERT、UPDATE、DELETE)都会生成 redo log
写入 redo log 在修改 Buffer Pool 之前
Redo Log 写入磁盘一般由 事务提交或刷新线程触发(顺序写入,性能高)
特点:
- 物理日志,按页记录变更,顺序写盘高效
- 崩溃恢复时,未刷盘的脏页通过 redo log 重新应用
- 生命周期:事务提交后仍保留 redo log,供崩溃恢复使用
总结:Redo Log 先于数据页刷盘,是事务持久性的保障。
# 3. Undo log(回滚日志)
和 Redo Log 相对,Undo Log 记录的是数据修改之前的旧值,它的主要作用是实现事务的原子性(Atomicity)和隔离性(Isolation):
记录内容:
- 逻辑日志,保存数据 修改前的旧值
- 每条记录包含修改字段、事务 ID、指向上一个版本的链表(Undo Segment)
触发条件:
- 任何修改数据的操作(UPDATE、DELETE,INSERT 对于回滚也需要记录)
- 事务开始时开始生成 Undo Log
- 回滚或隔离读取旧版本时使用
生命周期:
- 事务开始 → 开始记录 Undo Log
- 事务提交:
- Undo Log 不会立即删除
- 需要等待 相关事务结束 或 MVCC 不再访问该版本
- 后台线程(Purge Thread)负责清理
- 事务回滚 → 使用 Undo Log 回滚数据
总结:Undo Log 保存旧值,支持事务回滚和隔离,是 MVCC 的核心组件。
# 4. Binlog(归档日志)
Binlog(Binary Log)是 MySQL Server 层记录的逻辑日志,以事件(event)的形式记录所有的 DDL(如建表) 和 DML(如增删改) 操作。它不记录具体的数据页变更,而是记录对数据的操作行为,因此被称为逻辑日志。
记录内容:
- 逻辑级别日志,记录 DDL(建表、修改表结构)和 DML(增删改)的操作
- 不记录具体页或字段值,而是记录 操作行为(SQL 或行事件)
触发条件:
- 事务 提交时写入
- 成功提交才写,失败事务不记录
- 生成方式由 MySQL Server 层控制,与存储引擎无关
特点:
- 顺序追加写入文件,可循环切换
- 可通过
mysqlbinlog导出为 SQL 语句 - 用于主从复制、数据恢复、审计追踪
- 与 Redo/Undo 不同,逻辑日志存在 Server 层,而非存储引擎
总结:Binlog 记录事务逻辑操作,保证主从一致和可回溯。
# 5. 更新过程
update user set name = '1' where id = 1;
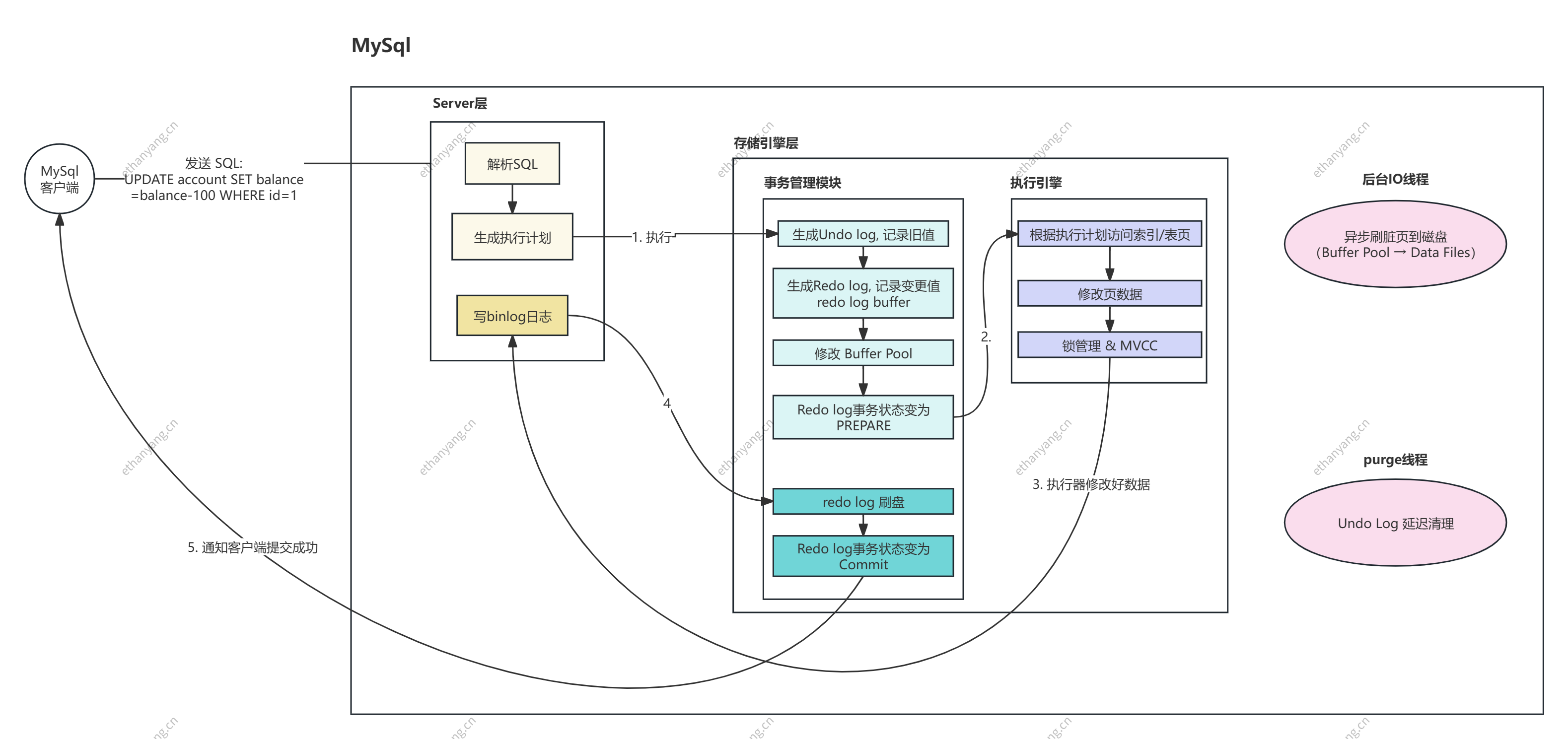
当执行上述 UPDATE 操作时,InnoDB 执行流程如下:
- 根据主键定位记录,并将对应数据页加载到 缓冲池(Buffer Pool);
- 生成对应的 Undo Log(记录旧值,用于回滚和 MVCC);
- 生成对应的 Redo Log(记录物理修改,用于崩溃恢复),并以
prepare状态刷入磁盘; - 修改缓冲池中的数据页内容(脏页),但此时数据尚未落盘;
- 至此,事务仍未提交,InnoDB 处于 二阶段提交的第一阶段(PREPARE)。
随后:
- Server 层生成并写入 Binlog(逻辑日志,用于主从同步、恢复和审计);
- 一旦 Binlog 写入成功,通知存储引擎将 Redo Log 状态从
prepare修改为commit,并完成刷盘; - 至此,事务提交完成,所有修改对外可见;
- 如果事务中存在失败操作,Binlog 不会记录该事务,Redo Log 事务状态标记为失败,恢复时会忽略失效事务。
⚠️ 注意:只有当 redo log 和 binlog 都成功写入后,事务才会真正提交,保证二者一致性(WAL + 2PC机制)。
Spring 事务伪代码解析
@Transcation(Exeception.class)
void test() {
更新数据库1;
更新数据库2;
业务代码;
}
2
3
4
5
6
第一阶段:执行 SQL,进入 Prepare 状态
- Spring 开启事务(通过 AOP 代理 + Connection 设置
autoCommit=false); - 执行
更新数据库1和更新数据库2时,InnoDB 内部流程:- 生成 Undo Log(记录旧值,用于回滚和 MVCC);
- 生成 Redo Log(记录物理修改,用于崩溃恢复),并以
prepare状态刷盘; - 修改缓冲池(Buffer Pool)中的数据页(脏页,暂未落盘);
- 此时事务仍未提交,对其他事务不可见。
第二阶段:根据方法执行结果决定 Commit 或 Rollback
情况一:业务代码执行成功
- Spring 事务拦截器调用
connection.commit(); - InnoDB 内部执行顺序:
- Server 层写入 Binlog(逻辑日志,用于主从复制、恢复和审计);
- 同步 Binlog 到磁盘;
- Redo Log状态从
prepare→commit并刷盘;
- 事务正式提交,所有修改对外可见;
- Undo Log 后续由后台线程延迟清理。
情况二:业务代码抛出异常(如 RuntimeException)
- Spring 捕获异常并触发
connection.rollback(); - InnoDB 使用 Undo Log 回滚缓冲池中已修改的数据;
- Redo Log 保持
prepare状态但不标记commit; - Binlog 不会写入,该事务不会同步到主从;
- 崩溃恢复时,InnoDB 会忽略未提交事务的 Redo Log,保证一致性。
索引深入解析 →