# 性能优化
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
# 连接配置优化
在高并发访问或连接泄漏等场景下,MySQL 容易出现如下报错:
ERROR 1040 (HY000): Too many connections
# 问题定位与原理说明
# 最大连接数限制
使用以下命令查看 MySQL 当前允许的最大连接数:
SHOW VARIABLES LIKE 'max_connections';
- 默认值一般为
151。 - 如果连接超过该值,新的连接会被拒绝,导致系统报错。
# 当前连接使用情况
SHOW STATUS LIKE 'Threads_connected'; -- 当前活跃连接数
SHOW STATUS LIKE 'Max_used_connections'; -- 历史最大连接数
2
- 可对比
max_connections与Max_used_connections,判断是否存在连接瓶颈。
# 空闲连接未释放
SHOW GLOBAL VARIABLES LIKE 'wait_timeout';
SHOW GLOBAL VARIABLES LIKE 'interactive_timeout';
2
- 默认空闲超时为
28800秒(8小时),配置过高可能导致大量长连接占用资源。
# 服务端优化策略
| 优化项 | 建议设置 | 说明 |
|---|---|---|
max_connections | 500+ | 根据并发数提升最大连接上限 |
wait_timeout | 60 ~ 300 | 释放长时间无活动的连接,防止资源浪费 |
interactive_timeout | 与 wait_timeout 保持一致 | 用于交互式连接 |
# 示例:配置文件调整(my.cnf)
[mysqld]
max_connections = 500
wait_timeout = 300
interactive_timeout = 300
2
3
4
⚠️ 提高
max_connections会增大内存占用,建议评估硬件资源后谨慎调整。
# 客户端优化策略(核心)
服务端设置再高,若客户端连接管理不当,仍可能触发连接耗尽。推荐如下优化措施:
# 启用连接池
- 推荐连接池:
HikariCP、Druid、C3P0 - ORM 框架如
MyBatis、Hibernate已集成连接池配置 - 连接池作用:
- 控制最大并发连接数(防止撑爆服务端)
- 实现连接复用
- 提供空闲连接回收机制
# 常见连接池配置示例(以 Druid 为例)
# 最大连接数
druid.maxActive=100
# 最小空闲连接
druid.minIdle=10
# 最大等待时间
druid.maxWait=60000
# 空闲连接超时时间(毫秒)
druid.minEvictableIdleTimeMillis=300000
# 定期检测空闲连接
druid.timeBetweenEvictionRunsMillis=60000
2
3
4
5
6
7
8
9
10
# 编码注意事项
- 必须手动释放连接(如
resultSet.close()、statement.close()、connection.close()) - 关闭连接一定要放在
finally中,防止异常跳过 - 避免频繁创建/关闭连接,应尽量使用连接池管理生命周期
# 架构优化
# 缓存
对于访问频繁、查询较慢的数据,可采用本地缓存(如 Caffeine)+分布式缓存(如 Redis)构建二级缓存架构,实现高可用、高性能的数据访问。
- 一级缓存(本地缓存):存放热点数据,避免频繁访问远程服务或数据库,响应速度快;
- 二级缓存(远程缓存):存放大部分常用数据,实现共享缓存,具备较好的容量与一致性保障;
- 缓存预热 + 缓存更新策略:结合数据生命周期合理设置过期时间,或使用消息队列/订阅方式主动更新缓存。
# 数据库集群与主从复制
MySQL 支持通过 主从复制 实现集群部署,实现读写分离、提升系统吞吐能力。
- 所有更新操作(如 INSERT/UPDATE/DELETE)都会记录到主库的 binlog(二进制日志);
- 从库通过 I/O 线程 连接主库,拉取 binlog 写入 中继日志(relay log);
- 从库的 SQL 线程 读取中继日志并重放 SQL 语句,完成数据同步。
| 角色 | 描述 |
|---|---|
| 主库 Log Dump 线程 | 向从库发送 binlog |
| 从库 I/O 线程 | 接收 binlog 写入中继日志 |
| 从库 SQL 线程 | 解析 relay log 并执行 |
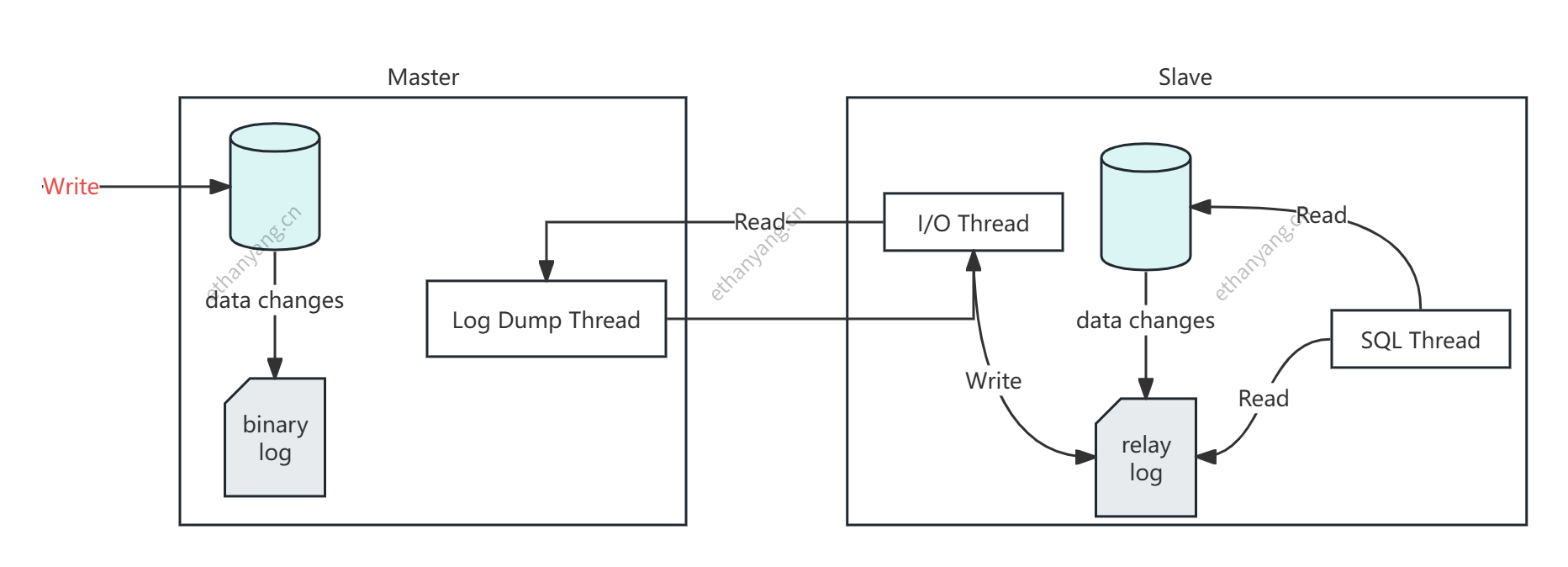
做了主从复制配置后, 就可以实现读写分离, 写的请求分配到master, 读的请求分配到slave节点。
# 分库分表策略
应对单表数据量过大或单库压力过重的问题,可以进行 分库分表,主要包括两种方式:
# 垂直分库(Vertical Sharding)
按业务领域将数据拆分到多个数据库中,例如:
- 用户库(user_db)
- 订单库(order_db)
- 支付库(payment_db)
目标:实现服务解耦,提升各业务线的独立性与性能。
# 水平分表(Horizontal Sharding)
将同一张表的数据按某种规则(如用户 ID 哈希或时间范围)拆分到多个表/库中,例如:
user_0,user_1, ...,user_15- 或按年月拆分
order_2024_01,order_2024_02, ...
目标:缓解单表数据量过大的性能瓶颈,提升查询效率。
# SQL语句分析与优化
# 慢查询日志
慢查询日志是 MySQL 性能优化中非常重要的工具,主要用于记录执行时间超过阈值的 SQL 语句,帮助定位性能瓶颈。
# 打开日志
方法 1:配置文件中开启(推荐)
在 my.cnf 或 my.ini 配置文件中添加以下配置:
slow_query_log = 1
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 1 # 单位:秒,表示超过 1 秒就记录为慢查询
log_queries_not_using_indexes = 1 # 记录未使用索引的查询
2
3
4
修改后重启 MySQL 服务使其生效。
方法 2:运行时动态开启
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
SET GLOBAL log_output = 'FILE'; -- 或 TABLE,记录到表中
2
3
# 慢日志分析
日志内容
慢查询日志一般格式如下:
# Time: 2025-06-24T11:31:22.123456Z # User@Host: root[root] @ localhost [] # Query_time: 3.021457 Lock_time: 0.000000 # Rows_sent: 1000 Rows_examined: 1000000 use mydb; SELECT * FROM users WHERE name LIKE '%ethan%';1
2
3
4
5
6重点关注字段:
- Query_time:查询耗时
- Lock_time:锁等待时间
- Rows_examined:扫描的行数,评估索引命中率
- Rows_sent:实际返回行数
使用
mysqldumpslow工具分析MySQL 提供
mysqldumpslow工具,用于归类和排序慢查询日志:mysqldumpslow -s r -t 10 /var/log/mysql/mysql-slow.log1常用参数:
-s r:按返回记录数排序(也可使用t代表时间)-t 10:显示前 10 条-g pattern:通过正则匹配查询语句
# 其它系统命令
慢查询不一定是 SQL 编写问题,也可能是服务器负载高、IO 瓶颈、锁等待等引起。可使用以下命令进行辅助分析:
# 查看系统资源
top # 查看 CPU、内存、负载情况
htop # 更直观的进程分析(需安装)
iostat -x 1 10 # 查看磁盘 I/O 情况(需安装 sysstat)
vmstat 1 10 # 查看内存、CPU、I/O 使用情况
free -m # 查看内存使用详情
2
3
4
5
# 查看 MySQL 内部状态
SHOW PROCESSLIST; -- 查看当前连接与执行中的 SQL
SHOW ENGINE INNODB STATUS; -- 查看 InnoDB 的内部运行状态(锁等待等)
SHOW GLOBAL STATUS LIKE 'Handler%'; -- 了解表级/索引级读写情况
2
3
# EXPLAIN 执行计划
现在已经可以确定是哪条SQL比较慢, 为什么慢要使用执行计划来定位。
以如下案例演示
-- 删除表(如果存在)
DROP TABLE IF EXISTS course;
DROP TABLE IF EXISTS teacher;
DROP TABLE IF EXISTS teacher_contact;
-- 创建 course 表
CREATE TABLE course (
cid INT(3) PRIMARY KEY,
cname VARCHAR(50) DEFAULT NULL,
tid INT(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 创建 teacher 表
CREATE TABLE teacher (
tid INT(3) PRIMARY KEY,
tname VARCHAR(20) DEFAULT NULL,
tcid INT(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 创建 teacher_contact 表
CREATE TABLE teacher_contact (
tcid INT(3) PRIMARY KEY,
phone VARCHAR(200) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入 course 数据
INSERT INTO course (cid, cname, tid) VALUES (1, 'mysql', 1);
INSERT INTO course (cid, cname, tid) VALUES (2, 'jvm', 1);
INSERT INTO course (cid, cname, tid) VALUES (3, 'juc', 2);
INSERT INTO course (cid, cname, tid) VALUES (4, 'spring', 3);
-- 插入 teacher 数据
INSERT INTO teacher (tid, tname, tcid) VALUES (1, 'qingshan', 1);
INSERT INTO teacher (tid, tname, tcid) VALUES (2, 'huihui', 2);
INSERT INTO teacher (tid, tname, tcid) VALUES (3, 'mic', 3);
-- 插入 teacher_contact 数据
INSERT INTO teacher_contact (tcid, phone) VALUES (1, '13688888888');
INSERT INTO teacher_contact (tcid, phone) VALUES (2, '18166669999');
INSERT INTO teacher_contact (tcid, phone) VALUES (3, '17722225555');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# explain字段详解
# 1. id
id是序列编号, 每张表都是单独访问的, 一个select就会有一个序号
id值不同的时候, 先查询id值大的(先大后小)
-- 查询 mysql 课程的老师手机号 EXPLAIN SELECT tc.phone FROM teacher_contact tc WHERE tc.tcid = ( SELECT t.tcid FROM teacher t WHERE t.tid = (SELECT c.tid FROM course c WHERE cname = 'mysql') )1
2
3
4
5
6![]()
如上案例, 表的查询顺序是 course -> teacher -> teacher_contact, 只有先拿到内存子查询的结果才能进行外层查询。
id值相同的时候, 查询顺序是从上往下顺序执行
-- 查询课程 ID为2,或者联系表 ID 为3的老师 EXPLAIN SELECT t.tname,c.cname,tc.phone FROM teacher t, course c, teacher contact tc WHERE t.tid = c.tid AND t.tcid = tc.tcid AND (c.cid = 2 OR tc tcid = 3);1
2
3
4
5
6
7
8![]()
如上案例, 表的查询顺序是 teacher -> course -> teacher_contact, 只有先拿到内存子查询的结果才能进行外层查询。


为什么会有id相同及不同的场景? 本质上id相同说明子查询被优化器转换成了连接查询, 从图中可以看出teacher 查了3条数据, course 4条, teacher_contact 1条, 再做连接查询时, 小表驱动大表。当ID既有相同又有不同的场景就需要结合来看, id不同先大后小, id相同从上往下。
# 2. select type 查询类型
select_type | 含义说明 |
|---|---|
SIMPLE | 简单查询,没有使用 UNION 或子查询。 |
PRIMARY | 最外层的 SELECT 查询(主查询)。 |
SUBQUERY | 子查询中 SELECT,出现在 WHERE 或 SELECT 中。 |
DERIVED | 衍生表的 SELECT(子查询出现在 FROM 子句中,MySQL 会创建临时表)。 |
UNION | 出现在 UNION 中的第二个或以后的 SELECT 语句。 |
UNION RESULT | 表示从 UNION 合并结果集中获取数据的查询。 |
DEPENDENT SUBQUERY | 子查询依赖于外部查询的结果(即子查询中的列依赖外部查询)。 |
DEPENDENT UNION | 与 UNION 类似,但依赖于外层查询。 |
MATERIALIZED | 子查询在执行前先计算并缓存结果(如 IN (SELECT...)),MySQL 8.0 引入。 |
UNCACHEABLE SUBQUERY | 不能被缓存的子查询(如依赖随机数或用户变量),每次执行都需重新计算。 |
# 3. type 连接类型
type | 说明 | 性能等级 |
|---|---|---|
system | 表仅有一行(系统表),是最高效的类型。 | 🟢 极高 |
const | 表最多只有一个匹配行,通常用于主键或唯一索引等等值查询。 | 🟢 极高 |
eq_ref | 通常出现在多表的 join 查询, 被驱动表通过唯一性索引(UNIQUE 或 PRIMARY KEY)进行访问, 此时被驱动表的访问方式就是eq_ref | 🟢 很高 |
ref | 使用非唯一索引或唯一索引的前缀来查找(多个匹配值)。 | 🟡 较好 |
| fulltext | 使用全文索引进行查询。 | 🟡 一般 |
| ref_or_null | ref 类型基础上,还会额外查找 NULL 值(如 WHERE col = ? OR col IS NULL)。 | 🟡 一般 |
| index_merge | 合并多个索引的结果进行查询。 | 🟡 一般 |
| unique_subquery | 子查询中使用唯一索引的等值查询(如 WHERE x = (SELECT id ...))。 | 🟢 较好 |
| index_subquery | 子查询中使用非唯一索引的等值查询。 | 🟡 一般 |
range | 索引范围扫描,如 BETWEEN、>、<、IN (...)。 | 🟡 一般 |
index | 遍历整个索引,类似全表扫描但只扫描索引树。 | 🔴 较差 |
ALL | 全表扫描,最差的一种方式。 | 🔴 很差 |
eq_ref 案例
-- ALTER TABLE teacher contact DROP PRIMARY KEY; ALTER TABLE teacher_contact ADD PRIMARY KEY(tcid); explain select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;1
2
3![]()
此时驱动表teacher 被驱动表teacher_contact, 可以看到被驱动表上的索引是主键索引, type就为eq_ref

一般来说, 需要保证查询的 type 至少达到 range 级别,最好能达到 ref。
# 4. possible_key key
可能用到的索引和实际用到的索引。如果是 NULL 就代表没有用到索引。
如果
possible_keys是NULL:- 通常说明 该 SQL 条件没有使用索引字段;
- 可能需要建索引;
- 或者是你用了函数、类型不匹配、隐式转换等导致索引失效。
如果
possible_keys有值但key = NULL:- 表示虽然有可用索引,但 优化器判断使用索引不如全表扫描划算;
- 通常出现在小表(例如只有几百行)或统计信息不准确时;
- 可尝试通过
FORCE INDEX强制使用某个索引进行验证。
如果
possible_keys = null但是key != null可能使用到了覆盖索引
-- 表结构 CREATE TABLE test ( id INT, name VARCHAR(100), INDEX idx_name(name) ); -- 查询语句, 没有使用where所以possible_keys = null, 但为了减少回表使用了idx_name来覆盖读取name EXPLAIN SELECT name FROM test;1
2
3
4
5
6
7
8
9
# 5. key_len
索引的长度, 略过。
# 6. rows
MySQL 认为扫描多少行才能返回请求的数据,是一个预估值。一般来说行数越少越好。
# 7. filtered
这个字段表示存储引擎返回的数据在 server 层过滤后, 剩下多少满足查询的记录数量的比例,它是一个百分比。该比例如果很低说明存储引擎层返回的数据需要经过大量过滤, 耗费性能。存储引擎根据索引查找可能符合的数据, SQL层处理 SQL 解析、优化、JOIN、WHERE、GROUP BY、HAVING 等逻辑。
# 8. ref
使用哪个列或者常数和索引一起从表中筛选数据。
# 9. Extra
额外信息
# 查询慢的优化总结
当我们遇到查询慢、连接卡顿等问题时,可以从 系统状态、SQL本身、架构设计 三个层面进行排查与优化:
# 服务端状态分析(连接层)
如果出现连接变慢、查询被阻塞、获取连接超时等现象,可以按以下步骤排查:
- 重启服务(临时缓解) 适用于线程堆积严重、连接耗尽等极端情况,作为紧急处理手段。
- 使用
SHOW PROCESSLIST查看连接状态- 检查连接数是否过多;
- 查看是否存在长时间执行的 SQL 或被锁住的连接;
- 关注状态字段(如:Sending data、Locked、Waiting for table metadata lock)。
- 排查锁相关问题
- 使用
SHOW ENGINE INNODB STATUS查看死锁; - 分析是否存在大事务或未提交事务导致锁长时间持有。
- 使用
- 杀掉异常线程
- 使用
KILL 线程ID手动释放异常连接资源。
- 使用
# 分析具体的慢 SQL(SQL 层)
# 1. 了解查询背景
- 涉及的表结构、字段及索引情况;
- 各表数据量级;
- 查询的业务意图是否明确,SQL 逻辑是否符合业务。
# 2. 使用执行计划分析(EXPLAIN)
- 查看表的访问顺序、访问方式(type);
- 是否命中索引(key);
rows、filtered、Extra等关键字段帮助判断执行效率;- 评估是否有全表扫描、临时表、排序等操作。
# 3. 找出真正的性能瓶颈
- 可以通过不断调整 SQL 的 条件顺序、过滤逻辑、写法结构 进行对比测试;
- 逐步缩小范围,定位慢查询的根源。
# 对症下药:SQL & 表结构优化
# 1. 索引优化
- 建立合适的单列或联合索引;
- 覆盖索引尽可能避免回表;
- 避免函数、模糊匹配造成索引失效。
# 2. 改写 SQL(经验积累尤为关键)
- 小表驱动大表:如 JOIN 时将数据量小的表放前面;
- 用 JOIN 替换子查询,避免嵌套查询性能差;
NOT EXISTS→LEFT JOIN ... IS NULL;OR替换为UNION,提升可用索引率;- 大 offset 的 LIMIT:通过子查询先筛选再分页;
- **避免 SELECT ***,仅查询所需字段。
# 表结构 & 架构层优化
# 1. 表结构优化
- 合理冗余,减少 JOIN;
- 将频繁查询但变动不大的字段冗余在主表中;
- 合理拆分大字段(如 TEXT、BLOB);
- 设置字段
NOT NULL可提升性能。
# 2. 架构优化
- 缓存:本地 + Redis 等远程缓存,减轻数据库压力;
- 读写分离:Master 写,Slave 读;
- 分库分表:按业务垂直拆分、按数据水平切分;
- 异步化:将非核心路径逻辑(如日志、通知)异步处理。
# 业务层优化
- 确保传入查询的参数 必要且有效,避免无谓的宽表扫描;
- 合理设置分页、默认排序等逻辑;
- 限流与降级机制,避免并发冲击数据库。
← 锁