# 分库分表
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
代码参考:[https://github.com/YangYingmeng/learning_shardingJDBC)
# 一、MySQL 数据库架构的演变
# 1. 数据库的演变升级
随着业务规模的扩大,数据库需要不断演进,以解决性能瓶颈、可用性不足、扩展性受限等问题。典型的演进路径如下:
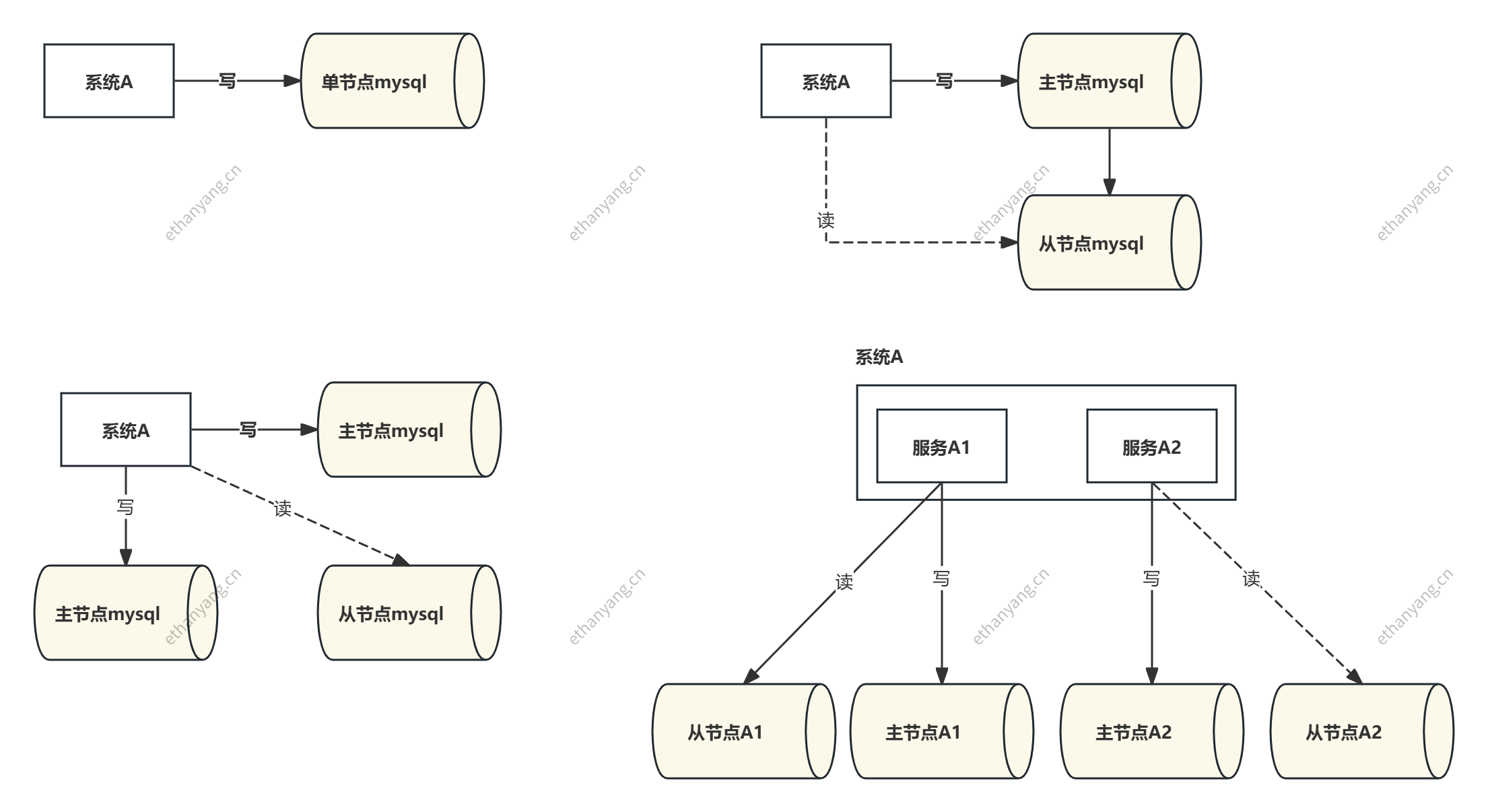
# 单机数据库
特点:
- 所有读写操作都集中在一个数据库实例上
- 架构简单、部署成本低
问题:
- 高并发下查询慢:CPU、内存、IO 都会成为瓶颈
- 单点故障(SPOF):一旦数据库宕机,业务完全不可用
- 无法横向扩展:性能提升只能依赖硬件升级(Scale Up)
# 主从架构(读写分离)
改进点:
- 引入从库,从库通过主库 异步/半同步 复制数据
- 主库负责写,从库实现 读扩展
优点:
- 提升整体读吞吐量
- 降低主库压力
- 一定程度上提升可用性(从库可作为备库)
但仍存在问题:
- 一个主库依然承担所有写压力 → 写成瓶颈
- 主库仍然是最终的 单点
- 主从同步延迟,读到旧数据的风险(读写一致性难保证)
- 增加从库无法解决核心瓶颈:TPS、IO、内存仍受限于主库机器
# 双主架构(多主写入)
为了解决单主写瓶颈,引入双主甚至多主架构。
改进点:
- 两个 Master 都可以处理写请求
- 互相同步 binlog,实现数据同步
优点:
- 写入能力提升
- 可在不同机房部署,提高可用性
但带来新的更大的挑战:
数据一致性极难保证(多主同步复杂)
- 主主之间要互相同步写操作,冲突检测难度大
- 可能出现写冲突、重复写、循环同步等问题
- 最终一致性难以保证,需要额外的机制(唯一键冲突、全局事务 ID 等)
架构复杂度显著提升
- 维护成本高
- 故障恢复流程困难
- 网络抖动可能导致严重的数据不一致
因此,多主更多用于:
- 跨地域多活
- 高可用容灾
- 对一致性要求不特别高的业务场景
# 分库分表(水平拆分)
当读写压力继续增大,单节点性能已无法满足需求,即使双主也不够时,数据库需要进行 水平扩展(Scale Out)。
核心思想: 将数据按照一定规则拆分成多个库(Sharding)和多个表(物理分库),使得:
- 多台数据库共同承担读写压力
- 单库数据量变小,查询速度更快
- 单表数据量可控,减少索引膨胀、加快扫描
优点:
- 真正实现数据库横向扩展
- 写能力、存储能力、读能力均可线性提升
挑战:
- SQL 路由(需要中间层)
- 跨库事务(CAP 限制)
- 跨库分页、排序复杂
- 数据迁移与扩容难度较高
分库分表是大规模业务的必经之路,但复杂度也随之提升,因此一般配合:
- 中间件如 ShardingSphere、MyCAT
- 自研分布式 ID
- 分布式事务补偿机制
- 缓存 / 搜索引擎协同
# 2. 分库分表的优缺点
分库分表(Sharding)的核心目的是突破单机数据库存储容量和并发性能的极限,实现数据库层面的水平扩展(Scale Out)。 它既能带来性能上的巨大收益,同时也会引入分布式系统的典型复杂性。
# 分库分表的优势
解决数据库连接数与并发瓶颈
单机 MySQL 默认最大连接数为 100,理论最大值 16384。当请求量大时,容易出现:
ERROR 1040 (HY000): Too many connections1分库后,多个数据库实例共同承接连接与请求压力,从根本上提升整体系统的并发能力。
缓解磁盘、网络、CPU 等硬件瓶颈
随着数据量增大,数据库会遇到三大硬件瓶颈:
磁盘 IO 瓶颈
数据量过大导致磁盘随机读写变慢
热点数据无法全部放入内存,导致大量 IO 访问
SQL 大表扫描会引起严重 IO 冲击
网络 IO 瓶颈
返回数据量大
同一数据库承载大量网络请求
链路延迟增高
CPU 瓶颈
复杂 SQL(排序、聚合、函数、跨表计算)会大量占用 CPU。
常见 CPU 高占用 SQL 状态:
- Sending data
- Copying to tmp table
- Sorting result
- Using filesort
- tmp table on disk
单库承担所有 SQL 运算时 CPU 容易打满。
# 分库分表带来的问题
跨节点 JOIN 查询受限
拆库后:
- 关联表不在同一库
- 无法直接执行 SQL JOIN(例如 JOIN、子查询)
跨库事务问题
数据不在同一个库时,原本依赖单机事务(ACID)的流程将受到影响,例如:
库 A:扣减库存 库 B:创建订单1
2这会引发:
- 2PC/3PC 成本高
- 全局锁与阻塞
- 数据不一致
- 分布式中间件参与
跨节点排序、分页、聚合问题
拆库后执行以下操作会变得复杂:
- ORDER BY
- LIMIT 分页
- GROUP BY
- COUNT、SUM、MAX、MIN 等函数
尤其是:
排序字段不是分片键时,所有节点需要先局部排序 → 再聚合 → 再全局排序。
全局主键唯一性问题
单库依赖自增 ID 时不会冲突,但分库后会有冲突。
分片扩容困难(数据迁移)
分库分表后的二次扩容通常面临:
- 是否需要扩容(2 库扩 4 库)
- 老数据如何导出迁移
- 分片键需不需要变更
- 如何保证迁移过程不停机
扩容属于最复杂的场景之一,需要工具和运维体系配合。
分库分表技术选型问题
这些问题的解决方案都会在后续章节中一一解答。
# 二、MySQL 常见的分库分表
# 1. 分库分表的常见方式
# 垂直分表
当 表字段过多、行数据宽度过大、存在大字段(text/blob)或访问频率差异明显 时,会将一张表拆分成多张。
拆分原则:
- 将不常用字段拆分到扩展表(减少主表宽度,提高缓存命中率)。
- 将大字段(text/blob)独立存储(减少 I/O 占用)。
- 将业务上经常一起查询的字段放在同一张表(避免跨表 join)。
主要目的:减小单表宽度、提升查询性能。
# 垂直分库
当某个数据库实例 CPU 长期高负载(>90%)、连接数频繁耗尽、单库成为瓶颈 时,将业务按功能拆分进不同数据库。
例:订单库、用户库、商品库分离 —— 对应微服务数据库拆分策略。
主要目的:分散压力,提高吞吐量。
# 水平分表
当 单张表数据量达到千万级甚至更高,影响查询与维护时,根据某种规则将数据拆到多个表中,但仍在同一个数据库里。
常见规则:
- 按创建时间分表(create_time)
- 按自增 ID 分片
- 按业务字段(如用户ID)分片
优点:
- 减少单表体积,提高查询效率
- 降低锁竞争时间
缺点:
- 数据仍在一个库,数据库 I/O、CPU 仍存在瓶颈
# 水平分库
在完成水平分表后,如果 一个数据库的I/O、CPU依然是瓶颈,需要将表组分布到不同物理数据库。
例:
- user_00 表放 DB1
- user_01 表放 DB2
主要目的:从根本上解决单库瓶颈,实现读写扩展能力。
# 2. 分库分表策略
# 水平分库分表的常见策略
基于 Range(范围)路由
根据某一字段的范围将数据分片。
常见规则:
- 按 ID 范围(如 0–1000w, 1000w–2000w)
- 按时间范围(按月、按季度、按年)
- 按地域范围(如:华东、华南 分库)
特点:
- 数据有明显区分
- 懒加载表、按需扩容容易
- 查询直观
缺点: 热点数据可能集中在某个区间,引发 分片热点问题
基于 Hash / 取模(Mod)路由
适用于 ID 离散性较好、数据均匀分布的场景。
规则示例:
table_index = user_id % 41对于非数字:
table_index = hash(username) % 41优点:分片数据分布比较均匀,不容易产生热点。
缺点:
- 一旦要扩容(从4张表扩到8张表),数据迁移成本大
- 历史数据需要重算 hash 并迁移
# 三、ShardingJDBC介绍
# 1. 常见术语与概念
# 数据节点
数据分片的最小执行单元,由 数据源名称 + 真实表 名称 组成。例如:
ds_0.product_order_0
每个 DataNode 对应一个具体的物理表。
# 真实表
在分片后 真正存在于数据库中的物理表,是最终 SQL 执行的目标表。
例如,同一个逻辑订单表拆分后:
product_order_0
product_order_1
product_order_2
2
3
# 逻辑表
多个真实表的统一抽象称为逻辑表,拥有一致的结构和业务含义。例如:
| 真实表 | 逻辑表 |
|---|---|
| product_order_0 | product_order |
| product_order_1 | product_order |
| product_order_2 | product_order |
开发者写 SQL 时只需要访问逻辑表,ShardingJDBC 会根据规则路由真实表。
# 绑定表
分片规则相同 的一组主从关联表。
例如订单主表和订单商品表都按照 order_id 分片:
product_order
product_order_item
2
绑定表的 JOIN 不会产生笛卡尔积,可直接精准路由,提高关联查询效率。
# ⼴播表
在所有数据源中都存在且内容一致的表。
常用于:
- 字典表
- 配置表
- 轻量、不会频繁更新的小表
存在于每个数据库中,可避免跨库 JOIN 提升性能。
# 2. 常见分片算法与策略
分片由 分片键(sharding column) + 分片策略(sharding strategy) 两部分组成。
# 分片键
用于决定数据库或数据表如何拆分的核心字段。
示例:订单表 product_order 根据订单号 out_trade_no 取模:
out_trade_no % 8 → 决定表路由
ShardingSphere 也支持 多字段联合分片,用于复杂场景下的路由控制。
# 分片策略
行表达式分片策略(InlineShardingStrategy)
特点:
- 仅支持单分片键
- 使用 Groovy 表达式
- 简单、高效、不需要 Java 代码实现
- 支持 SQL 中的
=和IN
示例:
product_order_$->{user_id % 8}1表示:
根据 user_id % 8 结果,路由到 product_order_0 ~ product_order_71适合结构简单、按规则分片的场景。
标准分片策略(StandardShardingStrategy)
特点:
- 仅支持单分片键
- 需要实现两个核心算法:
PreciseShardingAlgorithm(必选,用于=和IN)RangeShardingAlgorithm(可选,用于BETWEEN AND)
如果未配置
RangeShardingAlgorithm,且 SQL 使用区间查询:BETWEEN AND1则会触发 全库路由,性能会显著下降。
适合需要自定义复杂逻辑但只有一个分片键的场景。
复合分片策略(ComplexShardingStrategy)
特点:
- 支持多分片键
- 开发者自行实现分片逻辑
- 灵活度最高
- 支持处理
=,IN,BETWEEN AND等多种条件
适用于:
- 订单按
user_id和create_time双字段分片 - 高度定制化的业务场景
Hint 分片策略(HintShardingStrategy)
特点:
- 不依赖 SQL 中的分片键
- 分片信息由外部手动指定(HintManager)
- 完全绕过 SQL 解析
- 性能更高(尤其适用于复杂 SQL)
常见场景:
- 一个 SQL 通过某些业务逻辑决定只查某个分片
- 后台脚本批处理
- 某些 SQL 无法通过字段判断目标分片
示例:
HintManager.getInstance().setDatabaseShardingValue(1);1此时 SQL 会只在分片 1 中执行。
项目初始化 →