# Kafka 概念与实战
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
相关源码参考: KAFKA (opens new window)
# 快速认知:分布式流处理平台
Kafka 简介:
- 最初由 LinkedIn 开发,2010 年贡献给 Apache 基金会,成为顶级开源项目。
- 一个开源的 分布式事件流平台,由 Scala 和 Java 编写。
- 核心用途:处理用户行为等大数据流式数据(如网页浏览、搜索),广泛应用于 大数据实时处理领域。
Kafka 官网与文档:
核心角色初识:
- Broker:Kafka 服务端程序,即一个 MQ 节点,负责存储 Topic 数据。
- Producer:消息生产者,将消息发送到指定 Topic。
- Consumer:消息消费者,从 Topic 中消费消息。
# 核心概念详解
Broker:
- Kafka 的服务端程序,负责存储 Topic 数据。一个节点即一个 Broker。
Producer(生产者):
- 创建消息并发布到 Kafka 的 Topic 中。
Consumer(消费者):
- 从 Kafka 的队列中消费消息。
Consumer Group(消费者组):
- 多个消费者组成一个组,同一组内每条消息只被一个消费者处理;不同组间为广播模式。
Topic:
- 消息的分类标识,Producer 按 Topic 发布,Consumer 按 Topic 订阅。
Partition(分区):
- Kafka 存储的基本单元。一个 Topic 被划分为多个 Partition,可分布在不同节点。
- 每个 Partition 是有序的,Consumer 数量应 ≤ Partition 数量。
Replication(副本):
- Partition 的备份,提供容灾能力。默认每个 Topic 副本数为 1(节省资源)。
- 例如:3 个 Broker 的集群中,副本数最大为 3,超过会报错。
Leader / Follower(副本角色):
- 每个 Partition 的副本中,只有一个 Leader 负责与 Producer/Consumer 交互,Follower 从 Leader 同步。
ReplicationManager:
- 管理 Broker 中所有分区副本的信息和副本状态切换。
Offset(偏移量):
- Consumer 记录其消费到 Partition 的位置,Kafka 将 offset 保存在消费者组中。
# 特性总结
- 多订阅者:一个 Topic 可被多个消费者组订阅。
- 高吞吐、低延迟:每秒处理数十万条消息。
- 高并发:支持成千上万客户端并发读写。
- 容错性强:多副本、分区容灾机制,N 副本容忍 N-1 节点失败。
- 扩展性好:支持集群热扩容。
# 消费模型说明
- 队列模型:所有消费者在同一组,消息仅由一个 Consumer 处理。
- 发布订阅模型:不同组的消费者各自接收同一条消息,实现广播。
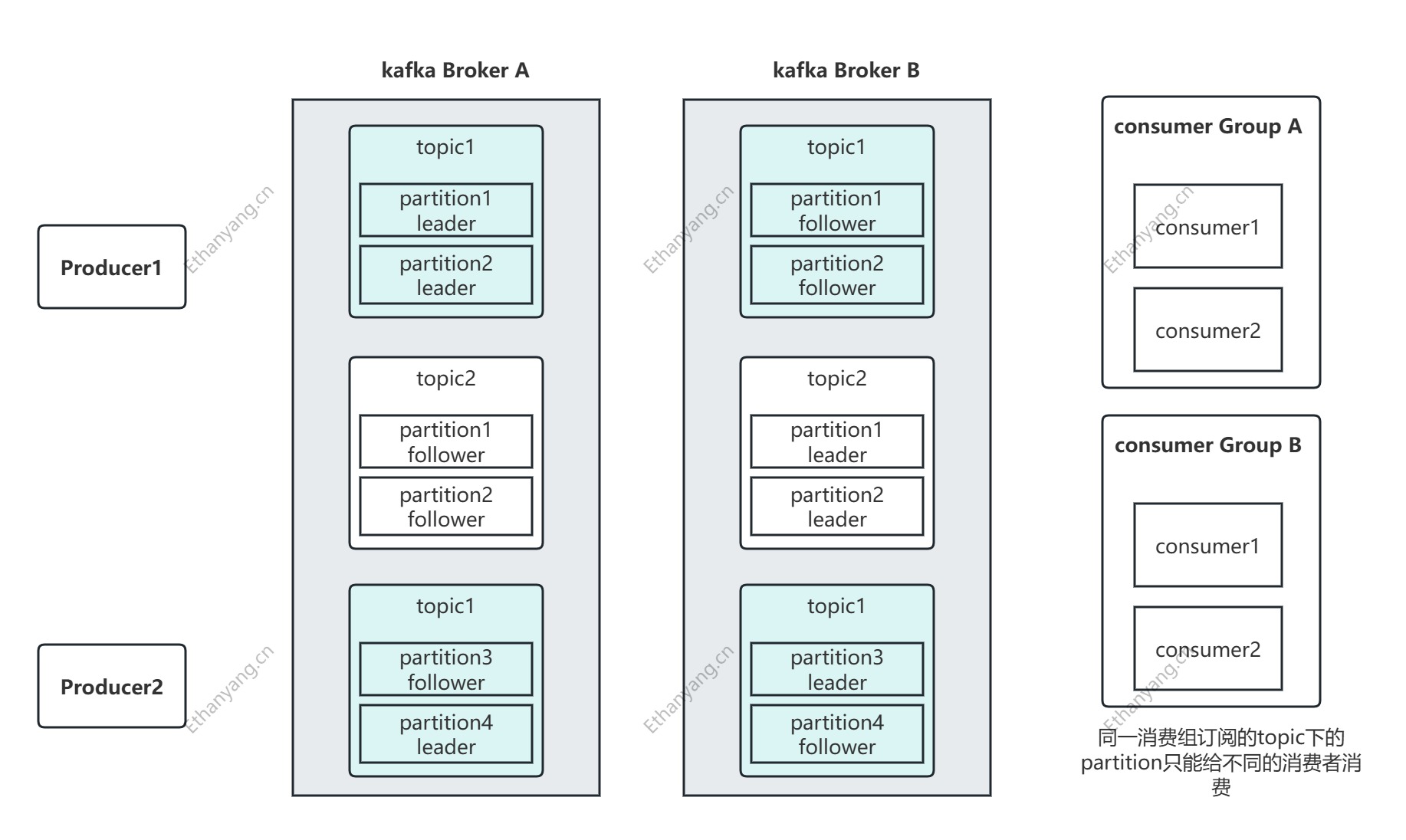
以该图为例, 有2个kafka节点(Broker), 以topic1为例, 有4个partition(leader), 4个leader的Replication (follower), 因为是备份, 同一个topic的partition的备份不需要放在同一个Broker上。zookeeper会在kafka集群中选一个controller, 该controller会负责分区分配以及分区的选举。partition可以认为是队列, kafka高吞吐相当于在topic内部做了分表
# 云服务器部署
jdk-11
下载安装自行查看
配置全局变量(vim /etc/profile)
JAVA_HOME=/www/server/java/jdk-11.0.19 CLASSPATH=$JAVA_HOME/lib/ PATH=$PATH:$JAVA_HOME/bin export PATH JAVA_HOME CLASSPATH1
2
3
4环境变量生效(source /etc/profile)
zookeeper安装
- 下载apache-zookeeper-3.7.0-bin.tar.gz并解压
- 复制/zookeeper/conf/zoo_sample.cfg 命名为 zoo.cfg
- 启动(bin/zkServer.sh start)
- 记得开放安全组(2181 默认端口)
kafka安装
下载kafka_2.13-2.8.0.tgz并解压
修改/kafka/config/server.properties
#修改下面两个配置 ( listeners 配置的ip和advertised.listeners相同时启动kafka会报错) listeners(内网Ip) advertised.listeners(公网ip) #修改zk地址,默认地址 如果zk和kafka在一台机器上 zookeeper.connection=localhost:21811
2
3
4
5
6守护进程方式启动
./kafka-server-start.sh -daemon ../config/server.properties &1记得开放安全组(9092默认端口)
# 点对点-发布订阅模型和写入存储流程
# 命令行生产者发送消息和消费者消费消息
简介: Kafka命令行生产者发送消息和消费者消费消息实战
创建topic
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic xdclass-topic1查看topic
./kafka-topics.sh --list --zookeeper 112.74.55.160:21811生产者发送消息
./kafka-console-producer.sh --broker-list 112.74.55.160:9092 --topic version1-topic1消费者消费消息 ( --from-beginning:会把主题中以往所有的数据都读取出来, 重启后会有这个重复消费)
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t11删除topic
./kafka-topics.sh --zookeeper 112.74.55.160:2181 --delete --topic t11查看broker节点topic状态信息
./kafka-topics.sh --describe --zookeeper 112.74.55.160:2181 --topic xdclass-topic1
# 点对点模型和发布订阅模型
简介: Kafka点对点模型和发布订阅模型讲解
- JMS规范目前支持两种消息模型
- 点对点(point to point)
- 消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息
- 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费
- 发布/订阅(publish/subscribe)
- 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。
- 和点对点方式不同,发布到topic的消息会被所有订阅者消费。
- 点对点(point to point)
# Kafka消费者组配置实现点对点消费模型
简介: Kafka消费者组配置实现点对点消费模型
- 编辑消费者配置(确保同个名称group.id一样)
- 编辑 config/consumer.properties
- 创建topic, 1个分区
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t1
- 指定配置文件启动 两个消费者
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer.properties
现象
- 只有一个消费者可以消费到数据,一个分区只能被同个消费者组下的某个消费者进行消费
# Kafka消费者组配置实现发布订阅消费模型
简介: Kafka消费者组配置实现发布订阅消费模型
- 编辑消费者配置(确保group.id 不一样)
- 编辑 config/consumer-1.properties
- 编辑 config/consumer-2.properties
- 创建topic, 2个分区
./kafka-topics.sh --create --zookeeper 112.74.55.160:2181 --replication-factor 1 --partitions 2 --topic t2
- 指定配置文件启动 两个消费者
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-1.properties
./kafka-console-consumer.sh --bootstrap-server 112.74.55.160:9092 --from-beginning --topic t1 --consumer.config ../config/consumer-2.properties
2
3
- 现象
- 两个不同消费者组的节点,都可以消费到消息,实现发布订阅模型
# 数据存储流程和原理概述和LEO+HW
简介: Kafka数据存储流程、原理、LEO+HW讲解
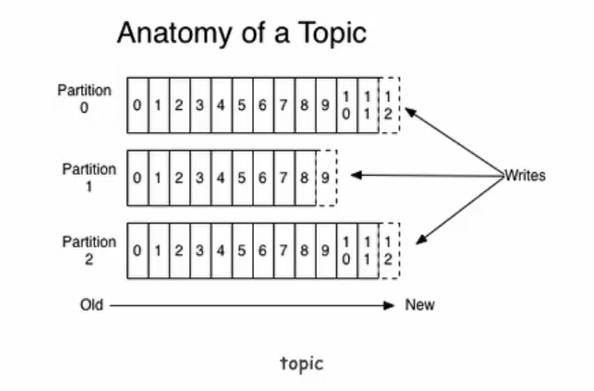
Partition
topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
是以文件夹的形式存储在具体Broker本机上
![]()
LEO(LogEndOffset)
- 表示每个partition的log最后一条Message的位置。如上图, partition 最后的虚线框部分。
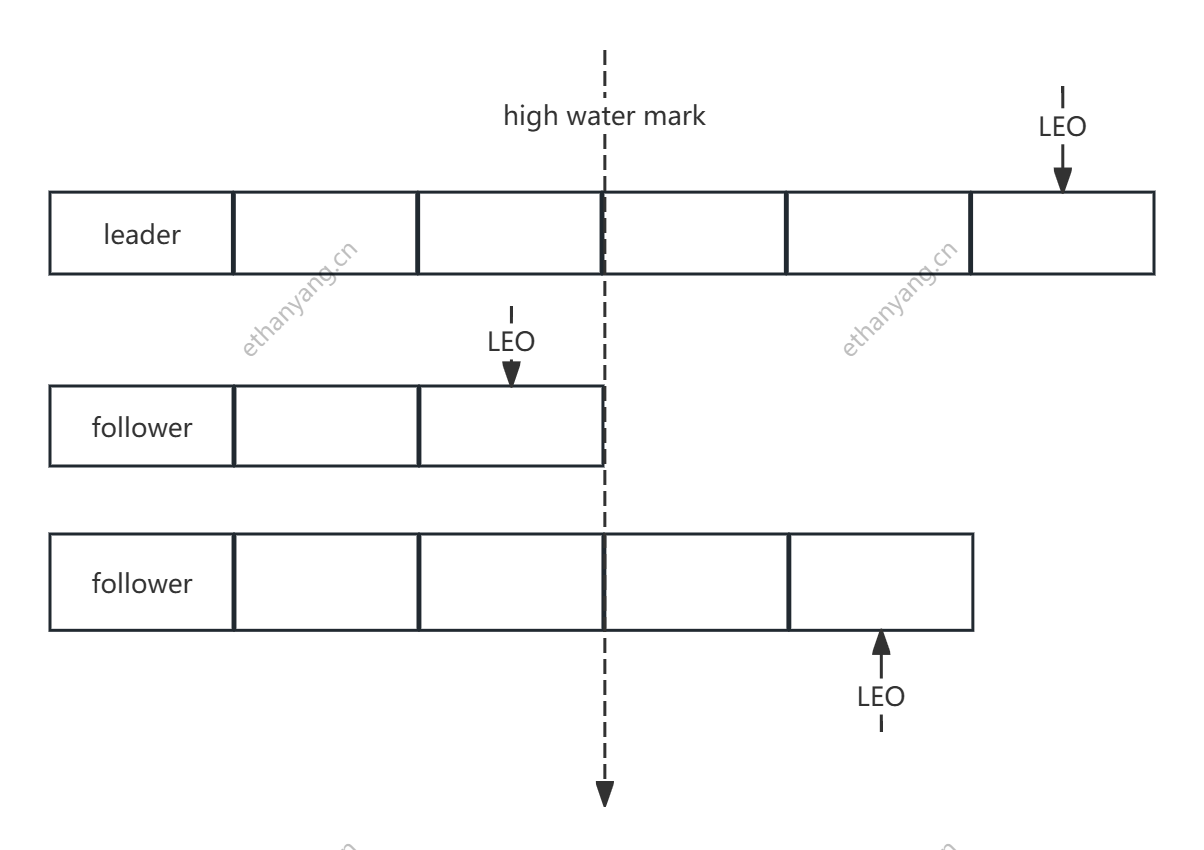
HW(HighWater mark)
- 表示partition各个replicas数据间同步且一致的offset位置,即表示allreplicas已经commit的位置
- HW之前的数据才是Commit后的,对消费者才可见
- ISR集合里面最小leo
![]()
offset:
- 每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中
- partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息
- 可以认为offset是partition中Message的id
Segment:每个partition又由多个segment file组成;
- segment file 由2部分组成,分别为index file和data file(log file),
- 两个文件是一一对应的,后缀”.index”和”.log”分别表示索引文件和数据文件
- 命名规则:partition的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset+1
Kafka高效文件存储设计特点:(结合concurrentHashmap 1.7 1.8思考)
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message
- producer生产数据,要写入到log文件中,写的过程中一直追加到文件末尾,为顺序写,官网数据表明。同样的磁盘,顺序写能到600M/S,而随机写只有100K/S
# Producer原理与核心API实战
# Producer整体结构原理讲解
Producer 发送消息流程:
- 构造消息(Record)
- 包括 topic、key(可选)、value
- 序列化
- key 和 value 序列化为字节数组(通过配置的
Serializer类完成)
- key 和 value 序列化为字节数组(通过配置的
- 分区器(Partitioner)选择 Partition
- 如果指定了 key,默认 hash 取模分区
- 如果没指定 key,采用轮询 Round-Robin 算法
- 发送消息到 RecordAccumulator
- Kafka 会把消息先放入缓冲池,异步批量发送,提升吞吐
- Sender线程发送请求
- Sender 是 Kafka 内部专门的线程,用于将消息打包成 batch 发送给对应的 Broker
- 网络 I/O
- 通过 Kafka 客户端的 NIO 机制发送数据
- Broker 接收写入消息,返回 ack
- 构造消息(Record)
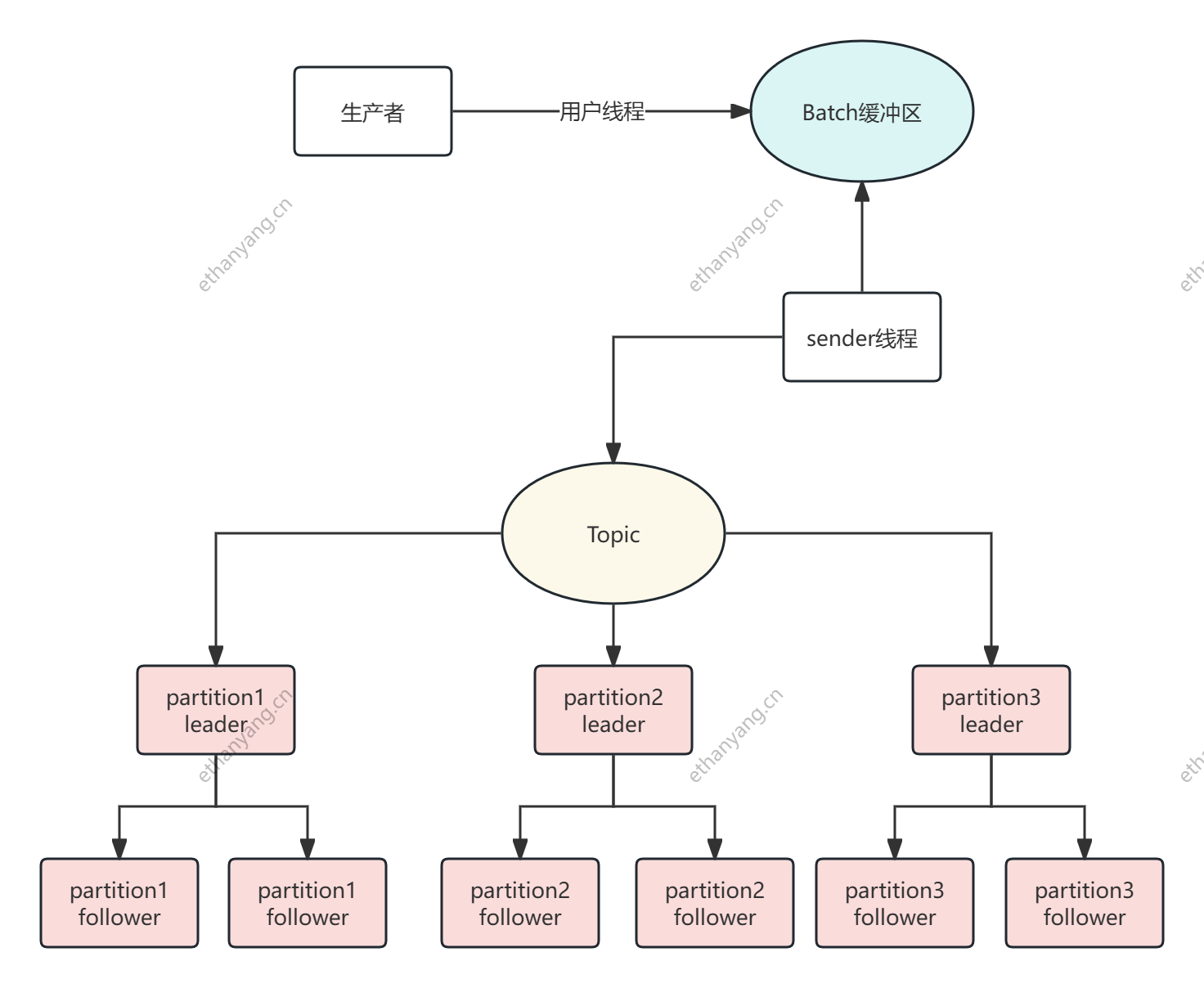
生产者到broker发送流程
- Kafka的客户端发送数据到服务器,不是来一条就发一条,会经过内存缓冲区(默认是16KB),通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集到的Batch里面,再一次性发送到Broker上去的,这样性能才可能题高
![]()
生产者常见配置
- 官方文档 http://kafka.apache.org/documentation/#producerconfigs
#kafka地址,即broker地址
bootstrap.servers
#当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
acks
#请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
retries
#每个分区未发送消息总字节大小,单位:字节,超过设置的值就会提交数据到服务端,默认值是16KB
batch.size
# 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满,如果想减少请求的数量,可以设置 linger.ms 大于#0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端
# 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
#如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
linger.ms
# buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
# 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器
# 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
# buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整
buffer.memory
# key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被设置,即使
#消息中没有指定key,序列化器必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将#key序列化成字节数组。
key.serializer
value.serializer
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 核心API模块-producer API
- 封装配置属性
public static Properties getProperties(){
Properties props = new Properties();
props.put("bootstrap.servers", "自己kafka的ip:9092");
//props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
// 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
// 0: 不确认 1: leader确认 all/-1 所有副本确认
props.put("acks", "all");
//props.put(ProducerConfig.ACKS_CONFIG, "all");
// 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
props.put("retries", 0);
//props.put(ProducerConfig.RETRIES_CONFIG, 0);
// 生产者缓存每个分区未发送的消息,缓存的大小是通过 batch.size 配置指定的,默认值是16KB
props.put("batch.size", 16384);
/**
* 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满
* 如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端
* 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送减少请求
* 如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
*/
props.put("linger.ms", 5);
/**
* buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
* 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器
* 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
* buffer.memory要大于batch.size,否则会报申请内存不#足的错误,不要超过物理内存,根据实际情况调整
* 需要结合实际业务情况压测进行配置
*/
props.put("buffer.memory", 33554432);
/**
* key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被设置,
* 即使消息中没有指定key,序列化器必须是一个实
org.apache.kafka.common.serialization.Serializer接口的类,
* 将key序列化成字节数组。
*/
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
return props;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
- 生产者投递消息API实战(同步发送)
/**
* send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
* 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
*
* 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
* 发送消息后返回的一个 Future 对象,调用get即可
*
* 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
* 1)main线程发送消息到RecordAccumulator即返回
* 2)sender线程从RecordAccumulator拉取信息发送到broker
* 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
*
*
*/
@Test
public void testSend(){
Properties properties = getProperties();
Producer<String,String> producer = new KafkaProducer<>(properties);
for(int i=0;i<3 ;i++){
// ProducerRecord 即消息, 指定key 分区时会对key进行hash, 不指定则轮询将消息放到不同的分区
// 未指定分区数, 默认为1 只有1个分区 消息自然全部进入同一个分区, 但是保证了消息的有序性
Future<RecordMetadata> future = producer.send(new ProducerRecord<>(TOPIC_NAME,"yym-key-noautocommit"+i, "yym-value"+i));
try {
//不关心结果则不用写这些内容
RecordMetadata recordMetadata = future.get();
// topic - 分区编号@offset
System.out.println("发送状态:"+recordMetadata.toString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# ProducerRecord 和 key 的作用
ProducerRecord(PR)
ProducerRecord 是发送给 Kafka Broker 的消息对象,包含以下信息:
- Topic(消息所属的主题)
- PartitionID(可选,指定消息的分区)
- Key(可选,用于消息分配)
- Value(消息内容)
key 的作用
- 默认情况下,key 为 null,Kafka 会采用 RoundRobin 算法将消息均匀分配到各个分区。
- 如果设置了 key,Kafka 会对其进行哈希计算,决定消息写入哪个分区。拥有相同 key 的消息会被写到同一分区,从而确保顺序消费。
# 核心API模块-producerAPI回调函数
- 生产者发送消息是异步调用,怎么知道是否有异常?
- 发送消息配置回调函数即可, 该回调方法会在 Producer 收到 ack 时被调用,为异步调用
- 回调函数有两个参数 RecordMetadata 和 Exception,如果 Exception 是 null,则消息发送成功,否则失败
- 异步发送配置回调函数
/**
* 发送消息携带回调函数
*/
@Test
public void testSendWithCallback(){
Properties properties = getProperties();
Producer<String,String> producer = new KafkaProducer<>(properties);
for(int i=0;i<3 ;i++) {
producer.send(new ProducerRecord<>(TOPIC_NAME, "yym-key" + i, "yym-value" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 回调函数异常为null即消息成功
if(exception == null){
System.err.println("发送状态:"+metadata.toString());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# producer生产者发送指定分区
- 创建topic,配置5个分区,1个副本
- 发送代码
/**
* 发送消息携带回调函数,指定某个分区
* 实现顺序消息
*/
@Test
public void testSendWithCallbackAndPartition(){
Properties properties = getProperties();
Producer<String,String> producer = new KafkaProducer<>(properties);
// 指定分区发送消息 就可以实现顺序消费消息
for(int i=0;i<10 ;i++) {
producer.send(new ProducerRecord<>("yym-v1-sp-topic-test", 4,"yym-key" + i, "yym-value" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.err.println("发送状态:"+metadata.toString());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 生产者自定义partition分区规则
- 源码解读默认分区器
org.apache.kafka.clients.producer.internals.DefaultPartitioner
自定义分区规则
- 创建类,实现Partitioner接口,重写方法
- 配置 partitioner.class 指定类即可
public class YymPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { if (keyBytes == null) { throw new IllegalArgumentException("key 参数不能为空"); } if("yym".equals(key)){ return 0; } List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/** * * 自定义分区策略 */ @Test public void testSendWithPartitionStrategy(){ Properties properties = getProperties(); properties.put("partitioner.class", "com.yym.kafka.config.YymPartitioner"); Producer<String,String> producer = new KafkaProducer<>(properties); for(int i=0;i<10 ;i++) { producer.send(new ProducerRecord<>("yym-v1-sp-topic-test", "yym", "yym-value" + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if(exception == null){ System.err.println("发送状态:"+metadata.toString()); } else { exception.printStackTrace(); } } }); } producer.close(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 核心 API 消费者模块
# Consumer 消费者机制和分区策略
消费者如何从 Broker 获取数据?
- Pull 模式:
Kafka 消费者采用 pull 拉取数据的方式,而不是 Broker 主动推送。
- 优点:消费者可以根据自己的消费能力调整拉取频率,避免处理不过来。
- 缺点:如果没有数据,消费者会根据配置的 timeout 阻塞等待一段时间。
- 为什么不是 Push 模式? 如果是 Broker 主动推送消息,虽然可以快速处理,但容易导致消费者消费能力不足,消息堆积,可能造成延迟。
- Pull 模式:
Kafka 消费者采用 pull 拉取数据的方式,而不是 Broker 主动推送。
消费者从哪个分区进行消费?
一个 Topic 可以有多个 Partition,而一个消费者组(Consumer Group)可以包含多个消费者。
每个 Partition 由一个消费者消费,但每个消费者组中的消费者不会重复消费同一个分区。
消费者分配策略
顶层接口
org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor1RoundRobinAssignor(轮询分配):
将所有 Partition 和 Consumer 按照消费者组进行轮流分配。
弊端
如果同一个消费者组的消费者监听同一个topic
- 当partition没法被所有的消费者均摊时, 会造成消费者分配不均
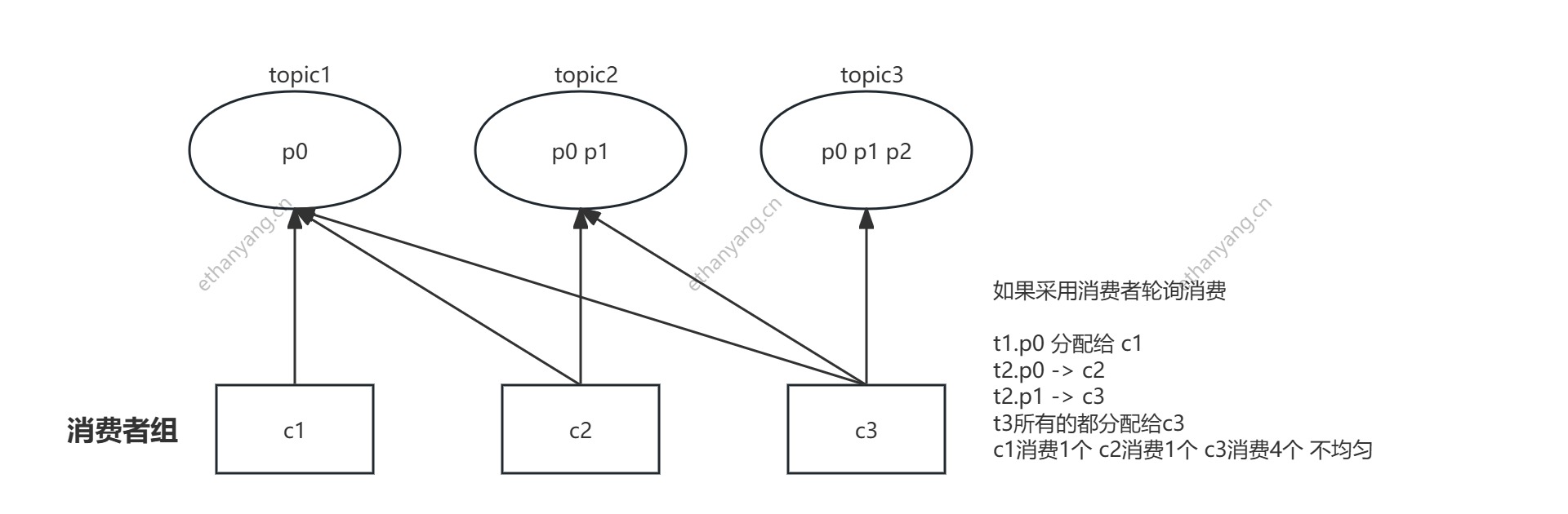
如果同一个消费者组的消费者监听不同的topic
以下图为例, c1 订阅 topic1, c2 订阅 topic1 topic2, c3 全部订阅会导致分配不均
![]()
RangeAssignor(范围分配):
按照每个 Topic 的 Partition 数量,依次将 Partition 分配给消费者。
- 按照主题的partition数量进行分配, 举例
- topic1(p0 p1) topic2(p0 p1 p2), 消费者组c1 c2 都订阅了
- c1(t1.p0) c2(t1.p1) c1(t2.p0) c2(t2.p1) c1(t2.p2)
- 弊端
- 只是针对 1 个 topic 而言,c-1多消费一个分区影响不大
- 如果有 N 多个 topic,那么针对每个 topic,消费者 C-1 都将多消费 1 个分区,topic越多则消费的分区也越多,则性能有所下降
- 按照主题的partition数量进行分配, 举例
# Consumer 重新分配策略和 Offset 维护机制
Rebalance 操作
Rebalance(重新平衡)是指 Kafka 在消费者组内消费者数量发生变化时,重新分配 Partition,确保每个消费者尽可能均衡地消费数据,避免过度负载。
Rebalance 触发条件:
- 消费者组内消费者数量变化(例如添加或移除消费者)。
- Topic 的 Partition 数量发生变化。
消费者宕机后的恢复
- Offset 记录:
Kafka 会记录消费者的消费进度(offset),确保消费者恢复后能从上次消费的位置继续消费。
- 该 offset 默认保存在 Kafka 内部的 __consumer_offsets 主题中,而不是 ZooKeeper 或本地。
- __consumer_offsets 主题有多个分区,Kafka 通过消费者组 ID 和分区哈希确定每个消费者的消费位置。
- 每个消费位点由 group.id + topic + partition 唯一标识,记录消费的 offset 和 metadata(如时间戳)。
- Offset 记录:
Kafka 会记录消费者的消费进度(offset),确保消费者恢复后能从上次消费的位置继续消费。
面试
例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配?
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 当消费者组内的消费者数量发生变化(增加或者减少),就会产生重新分配patition
- 分区数量发生变化时(即 topic 的分区数量发生变化时)
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
当消费者在消费过程突然宕机了,重新恢复后是从哪里消费,会有什么问题?
- 消费者会记录offset,故障恢复后从这里继续消费,这个offset记录在哪里?
- 记录在zk里面和本地,新版默认将offset保证在kafka的内置topic中,名称是 __consumer_offsets
- 该Topic默认有50个Partition,每个Partition有3个副本,分区数量由参数offset.topic.num.partition配置
- 通过groupId的哈希值和该参数取模的方式来确定某个消费者组已消费的offset保存到__consumer_offsets主题的哪个分区中
- 由 消费者组名+主题+分区,确定唯一的offset的key,从而获取对应的值
- __consumer_offsets 的 key:group.id+topic+分区号,而 value 就是 offset + metadata(时间戳)
- 不同的消费者组会消费同一个分区, 所以需要加groupId
# 消费者Consumer消费消息配置
- 配置
public static Properties getProperties() {
Properties props = new Properties();
//broker地址
props.put("bootstrap.servers", "自己kafka的ip:9092");
//消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
props.put("group.id", "yym-g1");
//默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效
props.put("auto.offset.reset","earliest");
//开启自动提交offset
//开启自动提交时,Kafka 会在指定时间间隔自动提交 offset,只要调用了 poll() 方法,
// 即使消费者还未处理或处理失败,Kafka 也会将 offset 向前提交,这可能导致未处理的消息被标记为已消费,从而造成消息丢失风险。
//props.put("enable.auto.commit", "true");
props.put("enable.auto.commit", "false");
//自动提交offset延迟时间
//props.put("auto.commit.interval.ms", "1000");
//反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 消费订阅
@Test
public void simpleConsumerTest(){
Properties properties = getProperties();
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题
kafkaConsumer.subscribe(Arrays.asList(_02KafkaProducerTest.TOPIC_NAME));
while (true){
//消费者向kafka拉取消息消费,响应的阻塞超时时间, 有消息及时返回, 没有则阻塞100ms
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
for(ConsumerRecord record : records){
System.err.printf("topic=%s, patition=%d, offset=%d,key=%s,value=%s %n",record.topic(),record.partition(), record.offset(),record.key(),record.value());
}
//同步阻塞提交offset
//kafkaConsumer.commitSync();
if(!records.isEmpty()){
//异步提交offset
kafkaConsumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if(exception == null){
System.err.println("手工提交offset成功:"+offsets.toString());
}else {
System.err.println("手工提交offset失败:"+offsets.toString());
}
}
});
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# Consumer从头消费配置和手工提交offset配置
如果需要从头消费partition消息,怎操作?
- auto.offset.reset 配置策略即可
- 默认是latest,需要改为 earliest 且消费者组名变更 ,即可实现从头消费
//默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效 props.put("auto.offset.reset","earliest");1自动提交offset问题
- 没法控制消息是否正常被消费
- 适合非严谨的场景,比如日志收集发送
手工提交offset配置和测试
- 初次启动消费者会请求broker获取当前消费的offset值
手工提交offset
- 同步 commitSync 阻塞当前线程 (自动失败重试)
- 异步 commitAsync 不会阻塞当前线程 (没有失败重试,回调callback函数获取提交信息,记录日志)
← MQ简介 数据文件存储-可靠性保证-高可用 →