# 并发基础
作者:Ethan.Yang
博客:https://blog.ethanyang.cn (opens new window)
# 一、并发编程概念
并发:指在同一时间段内,多个任务同时执行,且都未完成。可以理解为任务交替执行,由多个时间片构成一个时间段。
并行:指在某个单位时间内,多个任务真正同时执行,通常依赖于多核处理器的支持。
在单核 CPU 体系下,多个任务只能通过 CPU 调度进行切换,形成并发执行的效果,但实际仍然是串行执行。多线程编程在这种情况下可能会导致频繁的线程上下文切换,增加额外开销。例如,单核 CPU 运行多个线程时,线程之间需要不断等待 CPU 进行调度,如下图所示:

# 二、并发编程意义
随着多核 CPU 的普及,每个线程可以独占 CPU 核心进行计算,减少了单线程模式下的上下文切换开销。然而,在处理海量数据、并发请求等场景时,单线程已经无法满足高性能的需求,因此多线程并发编程成为提升系统吞吐量和响应速度的重要手段。
多线程的主要优势:
- 充分利用 CPU 资源:多核 CPU 允许多个线程同时执行,提高计算效率。
- 提高系统吞吐量:在 I/O 密集型任务(如网络请求、数据库查询)中,多线程可以在等待 I/O 期间执行其他任务,提升整体处理能力。
- 增强程序响应能力:在 GUI 程序或 Web 服务器中,使用多线程可以避免因单个任务阻塞而影响整体响应。
# 三、线程安全问题
共享资源:指多个线程能够访问或持有的资源,如全局变量、静态变量、数据库连接等。
线程安全问题:当多个线程同时读写共享资源且未采取同步措施时,可能会引发数据不一致、脏数据等问题。例如,在多线程环境下进行计数操作:
| 时间 | 线程 A | 线程 B | 内存 count |
|---|---|---|---|
| t1 | 读取 count=0 | 0 | |
| t2 | count + 1 = 1 | 读取 count=0 | 0 |
| t3 | 写回 count=1 | count + 1 = 1 | 1 |
| t4 | 写回 count=1 | 1 |
假设 count 初始值为 0,线程 A 和线程 B 同时执行自增操作:
t1:线程 A 读取count=0,准备进行自增。t2:线程 A 计算count+1=1,但还未写回内存,同时线程 B 读取count=0。t3:线程 A 将count=1写回主内存,而线程 B 此时仍然持有count=0。t4:线程 B 计算count+1=1,然后写回主内存,导致count仍然是1,丢失了一次递增操作。
尽管执行了两次递增操作,count 的最终值仍然为 1,导致数据不一致,这就是典型的共享变量的线程安全问题。
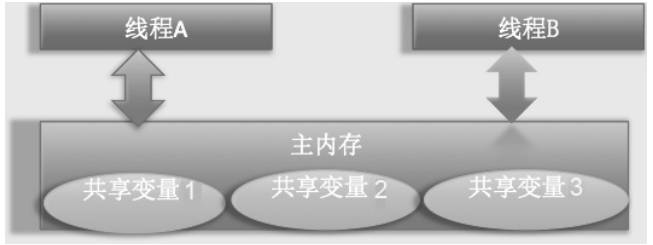
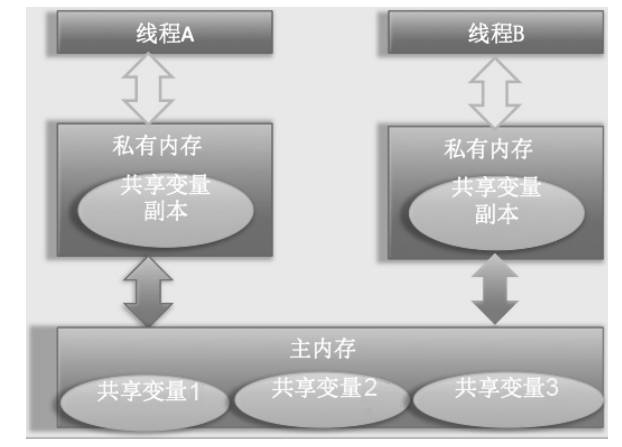
# 四、共享变量的内存可见性问题
在多线程环境下,每个线程都有自己的工作内存(缓存),它会从主内存中读取数据进行计算,并在某个时刻将修改后的数据写回主内存。这种缓存机制可能导致线程之间的数据不一致,形成内存可见性问题。
Java 内存模型(JMM,Java Memory Model)规定:
- 所有变量都存储在主内存中。
- 每个线程在使用变量时,都会从主内存复制到自己的工作内存(CPU 缓存或寄存器)。
- 线程对变量的修改不会立即同步到主内存,其他线程也无法立刻看到最新值。
如下图所示:
内存可见性问题的典型表现:
- 线程 A 修改了共享变量,但线程 B 仍然读取的是旧值,导致数据不一致。
- 线程 B 对变量的修改可能不会立刻反映到主内存中,影响其他线程的读取。
解决方案:
- 使用
volatile关键字,保证变量的可见性(但不保证原子性)。 - 采用
synchronized或Lock机制,确保线程安全。 - 使用 原子类(AtomicInteger 等) 来保证操作的原子性。
# 五、synchronized 和 volatile
在 Java 中,可见性问题 可以通过 synchronized 和 volatile 解决,它们在内存可见性和同步机制上各有不同的应用场景。
# synchronized
# 简介
synchronized 是 Java 提供的一种 内置锁(Monitor 锁),用于保证线程安全。每个对象都可以作为一把锁,当线程进入 synchronized 代码块时:
- 自动获取对象的内部锁,阻止其他线程进入该同步代码块。
- 线程执行完成或异常退出时,自动释放锁。
由于 Java 线程与操作系统的原生线程一一对应,synchronized 可能导致线程阻塞,触发用户态到内核态的切换,带来额外的上下文切换开销。因此,在高并发场景下需慎重使用。
# 内存语义
synchronized 既保证互斥性(同一时刻仅一个线程执行),也保证可见性(确保读取最新数据)。
- 进入
synchronized代码块时:- 线程会 清空工作内存中涉及的共享变量,确保从主内存获取最新数据。
- 执行
synchronized代码块:- 线程独占执行,防止竞态条件。
- 退出
synchronized代码块时:- 线程 必须将修改的变量刷新回主内存,确保其他线程可见。
这种内存语义由 Java 内存模型(JVM) 通过 内存屏障(Memory Barrier) 机制实现,使得 synchronized 具备 可见性 和 有序性。
# volatile
# 简介**
synchronized 解决了共享变量的可见性问题,但由于线程阻塞和上下文切换,性能开销较大。Java 提供了 volatile 关键字,作为更轻量级的可见性保证机制。
当变量被声明为 volatile 时:
- 线程 修改变量时,会立刻刷新到主内存。
- 其他线程 读取变量时,会直接从主内存获取最新值,而不是使用工作内存的缓存。
注意:volatile 不能保证原子性,它仅确保变量的可见性。
# 内存语义
- 写入
volatile变量时:- 修改值后立即同步到主内存。
- 读取
volatile变量时:- 强制从主内存获取最新值,不使用线程的本地缓存。
# 示例对比
以下是 synchronized 和 volatile 在变量同步中的使用对比:
// 非线程安全的共享变量
public class ThreadNotSafeInteger {
private int value;
public int get() {
return value;
}
public void set(int value) {
this.value = value;
}
}
// 使用 synchronized 解决并发问题(保证可见性和原子性)
public class ThreadSafeIntegerBySynchronized {
private int value;
public synchronized int get() {
return value;
}
public synchronized void set(int value) {
this.value = value;
}
}
// 使用 volatile 解决可见性问题(但不保证原子性)
public class ThreadSafeIntegerByVolatile {
private volatile int value;
public int get() {
return value;
}
public void set(int value) {
this.value = value;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
对比分析:
synchronized:保证原子性 + 可见性,但开销较大。volatile:仅保证可见性,不适用于复合操作(如i++仍然可能出现竞态条件)。
# 适用场景
- 使用
volatile:- 状态标志(如
boolean isRunning) - 轻量级的变量同步(不涉及复合操作)
- 状态标志(如
- 使用
synchronized:- 需要互斥访问的场景
- 复合操作(如
i++、a = b + c) - 需要保证原子性和可见性的复杂业务逻辑
# 六、原子性操作
在并发编程中,原子性指的是一系列操作要么全部执行,要么全都不执行,不会被其他线程干扰。
线程安全问题
计数器操作通常涉及 先读取当前值,再递增,如果无法保证该过程的原子性,在多线程环境下可能会导致线程安全问题。
示例对比:线程不安全 vs. 线程安全
public class ThreadNotSafeCount {
private Long value;
public Long getValue() {
return value;
}
public void increment() {
value++;
}
}
public class ThreadSafeCount {
private Long value;
public synchronized Long getValue() {
return value;
}
public synchronized void increment() {
value++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
synchronized 能确保原子性和可见性,但它是 排它锁,当一个线程访问 value 时,其他线程都会被阻塞,尤其是读操作也加锁,会影响性能。如果去掉 synchronized 只对 getValue() 解锁,仍然会导致数据可见性问题(脏读)。
更好的解决方案是使用 AtomicLong,它基于 CAS(Compare-And-Swap)算法,能高效保证原子性。
# 七、CAS操作
在使用锁时,线程可能会发生阻塞,频繁进行上下文切换和线程调度,从而增加系统开销。
volatile 关键字仅保证可见性,但无法确保操作的原子性。
CAS(Compare-And-Swap) 是 JDK 提供的一种非阻塞原子操作,通过硬件级别的支持确保比较-更新操作的原子性。Unsafe 类提供了一系列 CAS 相关的 API,以实现高效的并发控制。
# Unsafe类
Unsafe 是 Java 提供的一个低级 API,用于直接操作内存、对象实例化、CAS 操作等,通常用于高性能并发工具(如 AtomicInteger)、序列化框架(如 Kryo)等。
- 非安全:
Unsafe允许绕过 Java 语言层面提供的安全机制,直接操作内存,容易导致 JVM 崩溃或内存泄漏。 - 私有化构造:
Unsafe的构造方法是私有的,无法通过new直接实例化。 - 获取方式:可以通过反射获取
Unsafe实例。
public static Unsafe getUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
2
3
4
5
6
7
8
9
# 关键API
# 内存操作
Unsafe 提供了直接操作内存的方法,包括分配、释放、读写等。
直接分配 / 释放内存
long address = unsafe.allocateMemory(1024); // 分配 1024 字节内存 unsafe.freeMemory(address); // 释放内存1
2内存写入 / 读取
unsafe.putInt(address, 100); // 在指定地址写入 100 int value = unsafe.getInt(address); // 读取该地址的值1
2
# 对象操作
允许在不调用构造方法的情况下创建对象(序列化框架)
public class User {
private String name;
private int age;
}
User user = (User) unsafe.allocateInstance(User.class);
2
3
4
5
6
# 对象字段操作
获取字段偏移量
objectFieldOffset返回字段在对象中的内存偏移量,用于Unsafe直接访问字段。Field field = User.class.getDeclaredField("age"); long offset = unsafe.objectFieldOffset(field);1
2直接操作字段值
User user = new User(); unsafe.putInt(user, offset, 25); // 直接修改 user.age = 25 int age = unsafe.getInt(user, offset); // 读取 age1
2
3
# CAS操作
CAS 是无锁并发的基础,Unsafe 提供了底层支持, CAS 常用于 AtomicInteger 等类来实现无锁原子操作。
boolean success = unsafe.compareAndSwapInt(user, offset, 25, 30); // 期望值25,修改为30
# 数组操作
int baseOffset = unsafe.arrayBaseOffset(int[].class); // 获取数组起始地址
int indexScale = unsafe.arrayIndexScale(int[].class); // 获取数组元素大小(步长)
2
# 线程操作
挂起和恢复线程
unsafe.park(false, 0); // 挂起当前线程
unsafe.unpark(Thread.currentThread()); // 恢复线程
2
# 综合案例
// Unsafe 内部构造器私有, 不能new, 可以通过反射theUnsafe获取
// 该接口提供了很多操作内存 线程 cpu的底层API, 私有较为安全防止被误用
private static Unsafe unsafe;
static class Target {
private int value = 10;
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
}
@Before
public void setUp() throws Exception {
// 实例名称就叫theUnsafe
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
}
@Test
public void testObjectField() throws Exception {
Target target = new Target();
// unSafe 通过内存偏移量访问字段, 绕过了 Java的访问控制机制, 直接修改主内存数据, 并非工作内程数据
Field field = Target.class.getDeclaredField("value");
long offset = unsafe.objectFieldOffset(field);
assertEquals(10, unsafe.getInt(target, offset));
unsafe.putInt(target, offset, 20);
assertEquals(20, unsafe.getInt(target, offset));
}
@Test
public void testArrayOperations() {
int[] array = new int[] {1, 2, 3, 4};
int baseOffset = unsafe.arrayBaseOffset(int[].class);
int indexScale = unsafe.arrayIndexScale(int[].class);
assertEquals(16, baseOffset); // JVM 默认值,可能因环境变化
assertEquals(4, indexScale); // int 占 4 字节
long index1Address = baseOffset + indexScale;
assertEquals(2, unsafe.getInt(array, index1Address));
unsafe.putInt(array, index1Address, 100);
assertEquals(100, array[1]); // 修改成功
}
@Test
public void testCASOperation() throws NoSuchFieldException {
// CAS机制从硬件层面保证了原子性操作
Target target = new Target();
Field field = Target.class.getDeclaredField("value");
long offset = unsafe.objectFieldOffset(field);
assertTrue(unsafe.compareAndSwapInt(target, offset, 10, 50)); // CAS 成功
assertEquals(50, unsafe.getInt(target, offset)); // 值已变更
}
@Test
public void testOperation() throws NoSuchFieldException {
// 这种方式读写操作并非原子性操作, 可能会导致更新消失
Target target = new Target();
// 先读操作
if (target.getValue() == 10) {
// 再写操作
target.setValue(50);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# 八、Java 指令重排序
Java内存模型(JMM)允许编译器和处理器对指令进行重排序,以提高运行性能。编译器和处理器会根对没有数据依赖的指令进行重排序,以优化代码执行的效率。在单线程环境中,这种优化通常不会引发问题,但在多线程环境中,由于线程的执行顺序不可预测,指令重排序可能会导致数据不一致或不可预料的结果。
示例:
private static boolean flag = false;
private static volatile boolean volatileFlag = false; // 使用volatile确保可见性
private static int value = 0; // 共享变量
@Test
public void testUnSafe() throws InterruptedException {
Thread threadA = new Thread(() -> {
// 线程A修改共享变量
value = 42; // 指令1
flag = true; // 指令2
});
Thread threadB = new Thread(() -> {
// 线程B读取共享变量
if (flag) { // 指令3
System.out.println("value: " + value); // 指令4
}
});
// 指令重排序导致 打印结果不一致
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
@Test
public void testSafe() throws InterruptedException {
Thread threadA = new Thread(() -> {
// 线程A修改共享变量
value = 42; // 指令1
volatileFlag = true; // 指令2
});
Thread threadB = new Thread(() -> {
// 线程B读取共享变量
if (volatileFlag) { // 指令3
System.out.println("value: " + value); // 指令4
}
});
// 使用volatile关键字, 保证变量的修改对线程可见
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
volatile 的作用
- 写操作: 写入
volatile变量时,确保写入操作前的所有指令不会被重排序到写操作之后。即,value = 42不会被重排序到volatileFlag = true之后。 - 读操作: 读
volatile变量时,确保读操作后面的所有指令不会被重排序到读取操作之前。即,线程B在读取到volatileFlag时,它后面的value读取操作将确保读取到最新值。
通过使用volatile,可以确保变量的更新在多个线程之间可见,从而避免了由于指令重排序导致的数据不一致问题。
# 九、伪共享
伪共享(False Sharing)是由于多线程并发访问不同变量时,它们意外地位于同一个CPU缓存行内,导致缓存同步产生性能下降的一种现象。为了更好地理解伪共享,我们可以从计算机内存缓存模型的角度来分析。
# 内存缓存模型
现代计算机通常采用多级缓存架构,包括L1缓存、L2缓存等,它们位于CPU内部,距离CPU计算单元非常近,可以极大地提高访问速度。为了弥补CPU与主内存之间的速度差异,CPU会先在缓存(Cache)中查找需要的数据,只有当数据不在缓存中时,才会从主内存加载。
# 缓存行
- 缓存行是CPU缓存中的基本存储单位,通常每个缓存行大小为64字节(不同架构可能有所不同)。
- 当CPU访问内存中的某个变量时,它并不是单独加载该变量,而是把变量所在的缓存行(包含该变量的64字节内存区域)加载到CPU缓存中。
- 一个缓存行可能包含多个变量。
# 缓存一致性协议
由于现代计算机是多核的,每个核心通常有自己的L1和L2缓存,这就带来了一个问题:不同核心的缓存中的数据可能会不一致。为了保证多个核心之间的数据一致性,CPU会通过缓存一致性协议(如MESI协议)来协调缓存的更新。
# 伪共享如何发生的?
伪共享发生的根本原因是多个线程对不同变量的修改,可能导致这些变量位于同一个缓存行中。即使这些变量没有数据依赖性,但由于同一个缓存行只能由一个线程修改,导致多个线程同时修改不同变量时,必须频繁地同步缓存行。这种同步带来了不必要的性能损失。
# 伪共享的工作过程
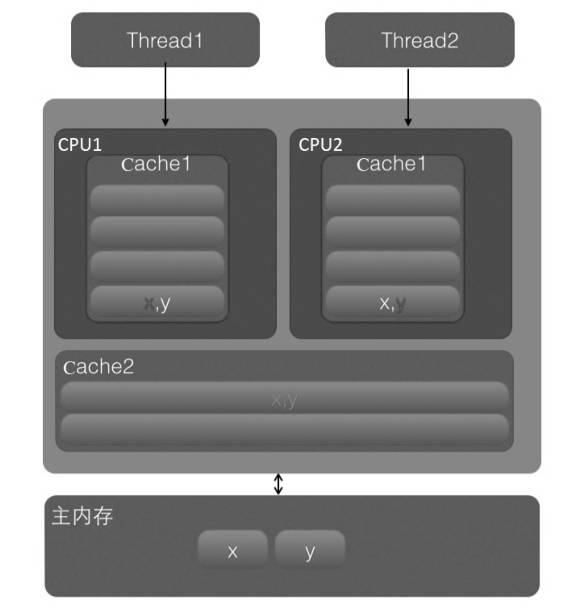
缓存行的共享: 假设有两个线程,线程1修改变量
x,线程2修改变量y,且x和y位于内存中的相邻位置,可能会被加载到同一个缓存行中。缓存行同步: 当线程1修改
x时,它会更新缓存行中的数据,并将更新后的缓存行标记为“脏”状态。线程2如果修改y,则会导致缓存行同步,因为x和y属于同一个缓存行。即使x和y之间没有数据依赖性,CPU仍然需要同步缓存行的状态。性能影响: 由于缓存行同步需要频繁地与其他核心的缓存进行协调,导致缓存行的同步成为性能瓶颈。多个线程虽然在操作不同变量,但由于这些变量位于同一个缓存行中,它们的访问会导致不必要的同步开销,从而降低整体性能。
# 如何避免伪共享?
调整变量布局: 通过调整内存布局,确保不同变量位于不同的缓存行中。可以通过在变量之间插入空白字段来填充内存,这样就能确保变量不会处于同一个缓存行内。
public class MyDataVoidFlaseSharing { public volatile long x = 0L; // 填充内存,确保x和y不在同一个缓存行 private long padding1, padding2, padding3, padding4, padding5, padding6; public volatile long y = 0L; }1
2
3
4
5
6使用
@Contended注解(JVM特性): 在Java中,可以使用@Contended注解来让JVM自动确保多个字段不共享同一个缓存行(需要配合JVM选项-XX:-RestrictContended)。public class MyDataVoidFlaseSharingContended { @Contended public volatile long x = 0L; @Contended public volatile long y = 0L; }1
2
3
4
5
6
# 十、锁
# 乐观锁与悲观锁
# 悲观锁
悲观锁的核心思想是认为数据很容易被其他线程修改,因此在数据处理前先加锁,确保整个处理过程中数据不会被其他线程修改。悲观锁通常依赖数据库的锁机制来实现,例如 SELECT ... FOR UPDATE 语句。
示例代码:
public int updateEntry(long id){
//(1)使用悲观锁获取指定记录
EntryObject entry = query("select * from table1 where id = #{id} for
update",id);
//(2)修改记录内容,根据计算修改entry记录的属性
String name = generatorName(entry);
entry.setName(name);
……
//(3)update操作
int count = update("update table1 set name=#{name},age=#{age} where id
=#{id}",entry);
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
事务提交时机
当事务传播机制为 REQUIRED 时,方法 updateEntry() 中的 查询 (query) 和更新 (update) 操作 都运行在同一个事务中。即:
query("SELECT ... FOR UPDATE")读取数据并加锁,但不会立即提交。- 只有
updateEntry()方法执行完成后,事务才会被统一提交。
为什么需要整个方法执行完才能提交事务?
这是因为 Spring 默认的 事务提交时机 是方法执行完毕后提交事务,即 "方法级别的事务管理":
- 事务在
updateEntry()方法开始时开启(如果上层没有事务)。 - 所有数据库操作都在该事务中执行,包括
query和update。 - 方法结束后,Spring 自动提交事务(或在发生异常时回滚)。
并发情况下的行为
多个线程调用 updateEntry(id):
- 如果传入相同的
id,第一个线程获取行级锁,其他线程必须等待它的事务提交或回滚,然后才能继续执行。 - 这保证了同一条记录不会被多个线程同时修改,避免并发冲突。
# 乐观锁
乐观锁 认为数据在大多数情况下不会发生冲突,因此在访问记录时不会加排它锁,而是在提交更新时检测是否发生数据冲突。其核心原理是:
查询数据 时获取
version(或其他状态字段)。更新数据 时,确保
version未发生变化(即WHERE version = ?)。通过
UPDATE影响的行数判断是否成功:
- 成功(
UPDATE影响行数 > 0):说明version未被修改,更新完成。 - 失败(
UPDATE影响行数 = 0):说明version已被其他线程修改,更新失败,可能需要重试或其他处理。
- 成功(
示例代码:
public int updateEntry(long id) {
// (1) 查询记录,获取当前 version
EntryObject entry = query("SELECT id, name, age, version FROM table1 WHERE id = #{id}", id);
if (entry == null) {
return 0; // 记录不存在
}
// (2) 计算修改后的值
String name = generatorName(entry);
entry.setName(name);
// (3) 使用乐观锁进行更新,确保 version 未被修改
int count = update(
"UPDATE table1 SET name = #{name}, age = #{age}, version = version + 1 " +
"WHERE id = #{id} AND version = #{version}",
entry
);
// (4) 返回更新结果,判断是否成功
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 公平锁与非公平锁
# 公平锁 vs. 非公平锁
- 公平锁:线程按照请求锁的先后顺序依次获取锁(FIFO)。
- 非公平锁:线程获取锁不考虑请求的顺序,可以直接尝试抢占锁,提高吞吐量。
示例代码:
@Test
public void testFairLock() {
// 创建公平锁
ReentrantLock fairLock = new ReentrantLock(true);
// 创建非公平锁(默认)
ReentrantLock unfairLock = new ReentrantLock(false);
}
2
3
4
5
6
7
# 为什么非公平锁性能更好?
公平锁的性能开销主要来自于两个方面:
- 线程切换成本高
- 公平锁需要维护一个等待队列,保证线程按照先来先得的顺序获取锁。
- 当锁被释放时,需要通知队列中最早等待的线程,可能涉及上下文切换,增加了开销。
- 竞争激烈时的吞吐量下降
- 非公平锁允许“抢占”,当锁释放时,当前线程或者新来的线程可以直接尝试获取锁,减少线程调度的等待时间。
- 公平锁则必须严格按照顺序,即使当前线程刚释放锁,仍然要让队列中最老的线程先执行,导致线程不能充分利用 CPU。
# 什么时候选择公平锁?
尽管非公平锁通常性能更好,但在以下情况,可能仍然需要使用公平锁:
- 需要严格保证先来先得,避免线程“饥饿”(如一些限流控制、银行转账等场景)。
- 业务对公平性要求较高,比如任务调度系统,确保任务按照提交顺序执行。
# 独占锁与共享锁
# 独占锁
概念
- 独占锁(又称写锁),指的是在同一时间只能有一个线程(或事务)获取该锁,其他线程无法同时获取,即使是读取操作也需要等待。
- 典型应用:
ReentrantLock、数据库SELECT ... FOR UPDATE、synchronized关键字。
示例
public class ExclusiveLockDemo {
private final ReentrantLock lock = new ReentrantLock(); // 默认是非公平锁
public void criticalSection() {
lock.lock(); // 获取独占锁
try {
System.out.println(Thread.currentThread().getName() + " 获取独占锁,执行关键操作...");
Thread.sleep(1000); // 模拟耗时操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock(); // 释放独占锁
}
}
}
@Test
public void testExclusiveLock() {
ExclusiveLockDemo demo = new ExclusiveLockDemo();
Runnable task = demo::criticalSection;
Thread t1 = new Thread(task, "线程A");
Thread t2 = new Thread(task, "线程B");
t1.start();
t2.start();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
特点
适用于需要保证数据一致性的场景,如数据库更新、临界区操作。 吞吐量较低**,因为同一时间只能有一个线程访问资源,可能导致其他线程长时间等待。
# 共享锁
概念
- 共享锁(又称读锁),指的是多个线程可以同时获取该锁进行读取,但如果有线程申请写操作(独占锁),则所有共享锁会被阻塞。
- 典型应用:
ReentrantReadWriteLock的 readLock()、数据库SELECT ... LOCK IN SHARE MODE。
示例
// 共享锁
public class SharedLockDemo {
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public void readOperation() {
lock.readLock().lock(); // 共享锁
try {
System.out.println(Thread.currentThread().getName() + " 获取共享锁,执行读取操作...");
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.readLock().unlock();
}
}
}
@Test
public void testSharedLock() {
SharedLockDemo demo = new SharedLockDemo();
Runnable task = demo::readOperation;
Thread t1 = new Thread(task, "线程A");
Thread t2 = new Thread(task, "线程B");
t1.start();
t2.start();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
特点
并发能力强,多个线程可同时读取数据,提高吞吐量。 不能写入数据,如果需要写操作,需要升级为独占锁。
# 可重入锁
概念
可重入锁,又称为递归锁,是一种可以由同一线程多次获取的锁。在该锁机制下,如果一个线程已经获取了锁,它可以再次获取该锁而不会发生死锁。这种锁允许同一线程在不同的代码段中多次获得锁,并且每次获取锁时都需要调用 unlock() 释放锁的次数才能真正释放锁。
特点
- 同一线程多次获得锁不会发生死锁。
- 每当线程获取锁时,锁的内部计数器会增加,
unlock()被调用时,计数器减少,直到计数器为 0 时才会真正释放锁。 - 提高代码的可重入性,避免因同一线程在多个地方加锁时出现死锁或无法正常解锁的情况。
实现原理
- 可重入锁通过为每个线程记录锁的持有次数来实现。当一个线程第一次获得锁时,锁的计数器值为 1。当同一线程再次请求该锁时,计数器值会增加。只有当锁的计数器值归零时,锁才会被释放。
示例代码:
// 可重入锁
public class ReentrantLockDemo {
private final ReentrantLock lock = new ReentrantLock();
// 方法A,调用方法B
public void methodA() {
lock.lock(); // 第一次获取锁
try {
System.out.println(Thread.currentThread().getName() + " 获取了锁,执行方法A");
methodB(); // 调用方法B
} finally {
lock.unlock(); // 解锁
}
}
// 方法B
public void methodB() {
lock.lock(); // 第二次获取锁
try {
System.out.println(Thread.currentThread().getName() + " 获取了锁,执行方法B");
} finally {
lock.unlock(); // 解锁
}
}
}
@Test
public void testReentrantLock() {
ReentrantLockDemo demo = new ReentrantLockDemo();
demo.methodA();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
解释
- 在上述代码中,
methodA()获取了锁,并在执行过程中调用了methodB()。由于methodB()中也请求了相同的锁,但是同一个线程main在同一个锁上重复请求时,锁并不会阻塞自己。 - 这种行为在没有可重入锁的情况下是不可行的,可能会导致死锁。
常见可重入锁实现
ReentrantLock:ReentrantLock是一种显式锁,支持可重入,并且提供比synchronized更强大的锁定控制,例如 公平性(公平锁)和 非公平性(非公平锁)的选择。
synchronized:- Java 的内置锁机制(
synchronized)本质上也是可重入的。即同一线程可以多次进入同步代码块而不被阻塞。
- Java 的内置锁机制(
# 自旋锁
概念
自旋锁 是一种通过反复检查某个条件是否满足而等待的锁机制。在自旋锁中,当一个线程试图获取锁时,如果锁已经被其他线程占用,线程不会被挂起或休眠,而是会在循环中“自旋”反复检查锁的状态。这种自旋操作可以减少上下文切换的开销,适用于锁持有时间非常短的场景。
自旋锁是一种轻量级的锁,它不像传统的阻塞锁(如 ReentrantLock)那样会将线程挂起,而是通过忙等待(不断轮询)来判断锁是否可用。
自旋锁的特点
- 无阻塞:线程不会进入操作系统的调度队列,而是会持续检查锁的状态,直到成功获取锁。
- 忙等待:线程会不断消耗 CPU 资源,执行一个短时间的自旋。
- 适用场景:适合锁持有时间非常短的场景,避免了线程阻塞和唤醒的开销。
- 性能消耗:自旋锁本身消耗 CPU 资源,因此不适用于锁持有时间长或竞争严重的情况。
示例代码:
// 自旋锁
public class SpinLock {
private volatile boolean flag = false; // 锁标志,false表示没有锁,true表示有锁
public void lock() {
while (true) {
if (!flag) {
if (compareAndSet(false, true)) { // 比较并设置标志位
return; // 成功获取锁
}
}
}
}
public void unlock() {
flag = false; // 释放锁
}
// 使用CAS(Compare And Swap)进行锁状态的原子操作
private boolean compareAndSet(boolean expected, boolean newValue) {
if (flag == expected) {
flag = newValue;
return true;
}
return false;
}
}
@Test
public void testSpinLock() {
SpinLock spinLock = new SpinLock();
Runnable task = () -> {
spinLock.lock(); // 获取锁
try {
System.out.println(Thread.currentThread().getName() + " 获取锁,执行操作...");
try {
Thread.sleep(1000); // 模拟操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
} finally {
spinLock.unlock(); // 释放锁
System.out.println(Thread.currentThread().getName() + " 释放锁");
}
};
Thread t1 = new Thread(task, "线程A");
Thread t2 = new Thread(task, "线程B");
t1.start();
t2.start();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
解释
- 在上述示例中,
SpinLock类实现了一个简单的自旋锁。通过flag变量控制锁的状态。当lock()被调用时,线程会通过compareAndSet()方法检查并设置flag,如果锁未被占用,则成功获取锁并进入临界区。 - 这个示例展示了一个典型的自旋锁操作,线程会不断自旋,直到成功获取锁。